
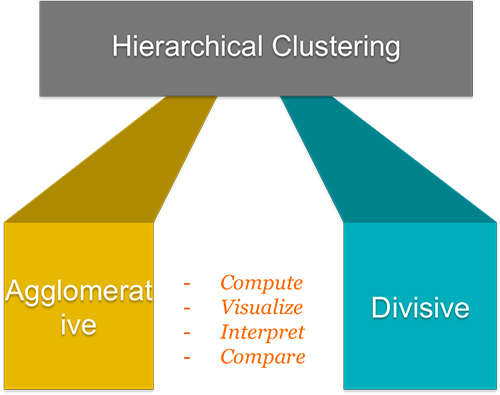

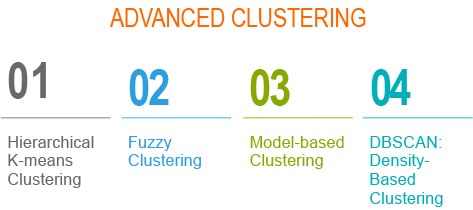
Types of Clustering Methods: Overview and Quick Start R Code
By
kassambara,
The
in Cluster Analysis in R: Practical Guide
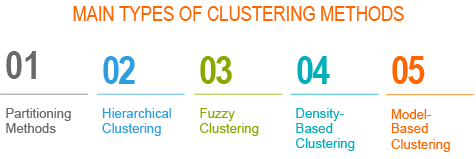
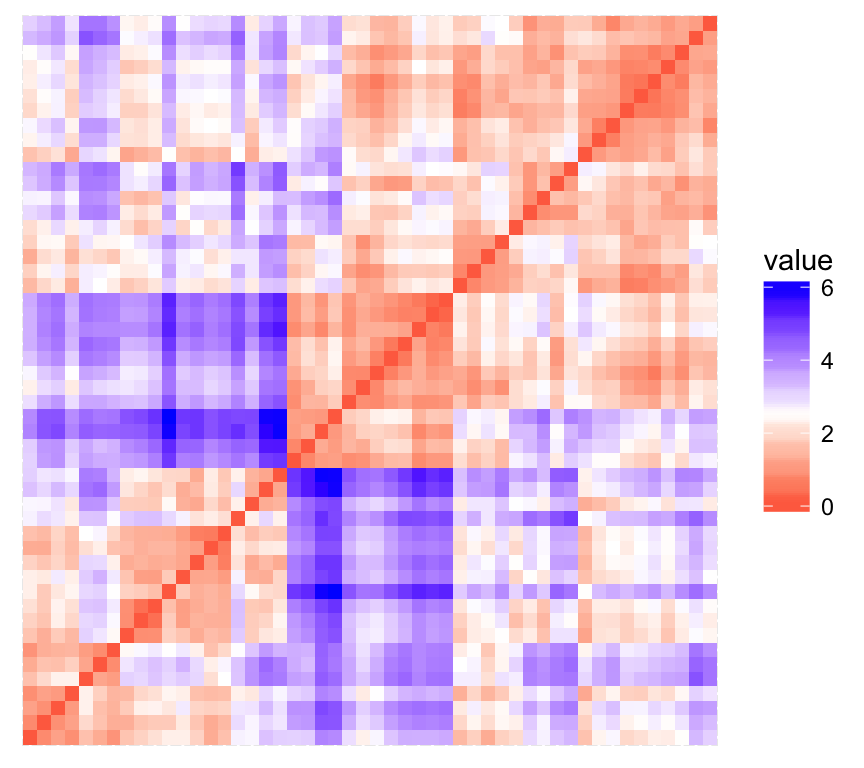
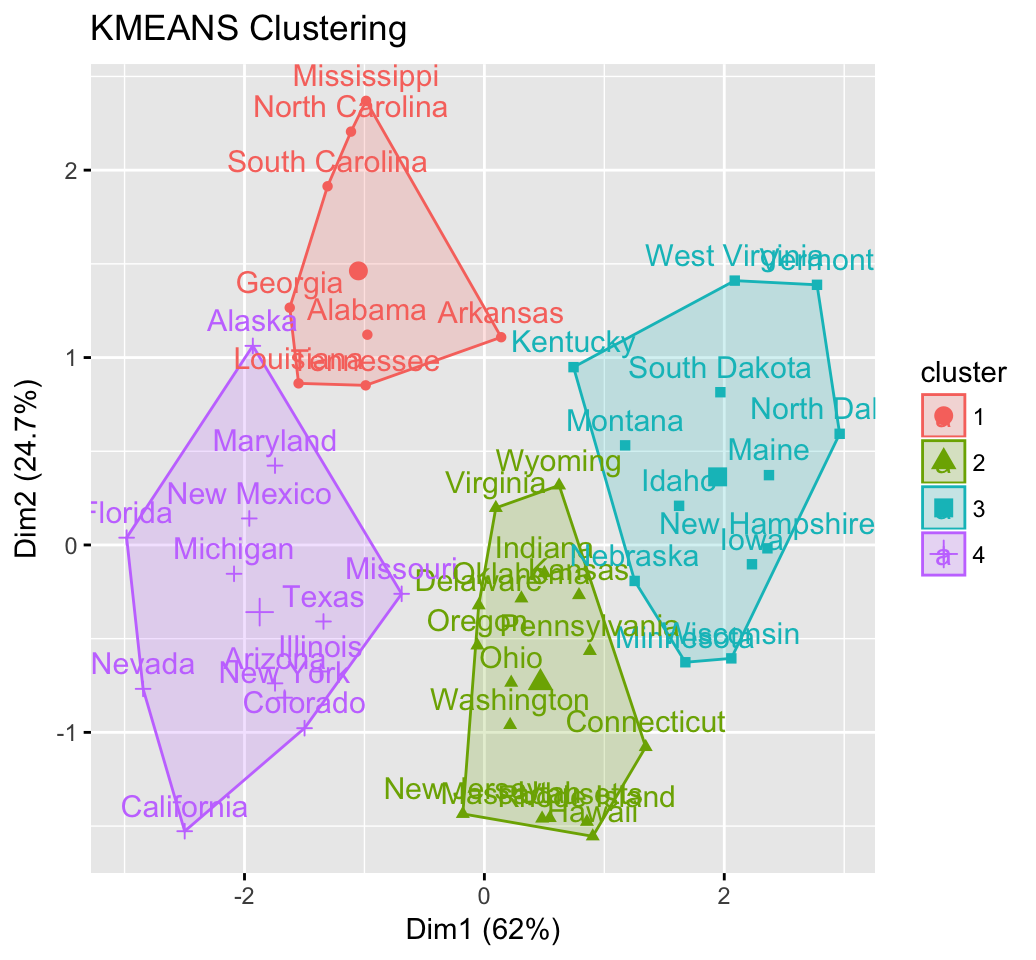
Clustering methods are used to identify groups of similar objects in a multivariate data sets collected from fields such as marketing, bio-medical and geo-spatial. They are different types of... [Read more]