


Factoextra R Package: Easy Multivariate Data Analyses and Elegant Visualization
factoextra is an R package making easy to extract and visualize the output of exploratory multivariate data analyses, including:
Principal Component Analysis (PCA), which is used to summarize the information contained in a continuous (i.e, quantitative) multivariate data by reducing the dimensionality of the data without loosing important information.
Correspondence Analysis (CA), which is an extension of the principal component analysis suited to analyse a large contingency table formed by two qualitative variables (or categorical data).
Multiple Correspondence Analysis (MCA), which is an adaptation of CA to a data table containing more than two categorical variables.
Multiple Factor Analysis (MFA) dedicated to datasets where variables are organized into groups (qualitative and/or quantitative variables).
Hierarchical Multiple Factor Analysis (HMFA): An extension of MFA in a situation where the data are organized into a hierarchical structure.
Factor Analysis of Mixed Data (FAMD), a particular case of the MFA, dedicated to analyze a data set containing both quantitative and qualitative variables.
There are a number of R packages implementing principal component methods. These packages include: FactoMineR, ade4, stats, ca, MASS and ExPosition.
However, the result is presented differently according to the used packages. To help in the interpretation and in the visualization of multivariate analysis - such as cluster analysis and dimensionality reduction analysis - we developed an easy-to-use R package named factoextra.
The R package factoextra has flexible and easy-to-use methods to extract quickly, in a human readable standard data format, the analysis results from the different packages mentioned above.
It produces a ggplot2-based elegant data visualization with less typing.
- It contains also many functions facilitating clustering analysis and visualization.
We’ll use i) the FactoMineR package (Sebastien Le, et al., 2008) to compute PCA, (M)CA, FAMD, MFA and HCPC; ii) and the factoextra package for extracting and visualizing the results.
FactoMineR is a great and my favorite package for computing principal component methods in R. It’s very easy to use and very well documented. The official website is available at: http://factominer.free.fr/. Thanks to François Husson for his impressive work.
The figure below shows methods, which outputs can be visualized using the factoextra package. The official online documentation is available at: https://www.sthda.com/english/rpkgs/factoextra.
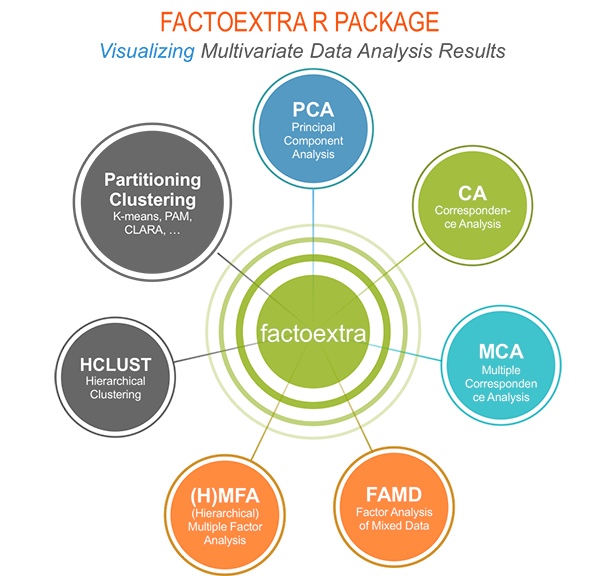
Why using factoextra?
The factoextra R package can handle the results of PCA, CA, MCA, MFA, FAMD and HMFA from several packages, for extracting and visualizing the most important information contained in your data.
- After PCA, CA, MCA, MFA, FAMD and HMFA, the most important row/column elements can be highlighted using :
- their cos2 values corresponding to their quality of representation on the factor map
- their contributions to the definition of the principal dimensions.
If you want to do this, the factoextra package provides a convenient solution.
- PCA and (M)CA are used sometimes for prediction problems : one can predict the coordinates of new supplementary variables (quantitative and qualitative) and supplementary individuals using the information provided by the previously performed PCA or (M)CA. This can be done easily using the FactoMineR package.
If you want to make predictions with PCA/MCA and to visualize the position of the supplementary variables/individuals on the factor map using ggplot2: then factoextra can help you. It’s quick, write less and do more…
- Several functions from different packages - FactoMineR, ade4, ExPosition, stats - are available in R for performing PCA, CA or MCA. However, The components of the output vary from package to package.
No matter the package you decided to use, factoextra can give you a human understandable output.
Installing FactoMineR
The FactoMineR package can be installed and loaded as follow:
# Install
install.packages("FactoMineR")
# Load
library("FactoMineR")Installing and loading factoextra
- factoextra can be installed from CRAN as follow:
install.packages("factoextra")- Or, install the latest version from Github
if(!require(devtools)) install.packages("devtools")
devtools::install_github("kassambara/factoextra")- Load factoextra as follow :
library("factoextra")Main functions in the factoextra package
See the online documentation (https://www.sthda.com/english/rpkgs/factoextra) for a complete list.
Visualizing dimension reduction analysis outputs
| Functions | Description |
|---|---|
| fviz_eig (or fviz_eigenvalue) | Extract and visualize the eigenvalues/variances of dimensions. |
| fviz_pca | Graph of individuals/variables from the output of Principal Component Analysis (PCA). |
| fviz_ca | Graph of column/row variables from the output of Correspondence Analysis (CA). |
| fviz_mca | Graph of individuals/variables from the output of Multiple Correspondence Analysis (MCA). |
| fviz_mfa | Graph of individuals/variables from the output of Multiple Factor Analysis (MFA). |
| fviz_famd | Graph of individuals/variables from the output of Factor Analysis of Mixed Data (FAMD). |
| fviz_hmfa | Graph of individuals/variables from the output of Hierarchical Multiple Factor Analysis (HMFA). |
| fviz_ellipses | Draw confidence ellipses around the categories. |
| fviz_cos2 | Visualize the quality of representation of the row/column variable from the results of PCA, CA, MCA functions. |
| fviz_contrib | Visualize the contributions of row/column elements from the results of PCA, CA, MCA functions. |
Extracting data from dimension reduction analysis outputs
| Functions | Description |
|---|---|
| get_eigenvalue | Extract and visualize the eigenvalues/variances of dimensions. |
| get_pca | Extract all the results (coordinates, squared cosine, contributions) for the active individuals/variables from Principal Component Analysis (PCA) outputs. |
| get_ca | Extract all the results (coordinates, squared cosine, contributions) for the active column/row variables from Correspondence Analysis outputs. |
| get_mca | Extract results from Multiple Correspondence Analysis outputs. |
| get_mfa | Extract results from Multiple Factor Analysis outputs. |
| get_famd | Extract results from Factor Analysis of Mixed Data outputs. |
| get_hmfa | Extract results from Hierarchical Multiple Factor Analysis outputs. |
| facto_summarize | Subset and summarize the output of factor analyses. |
Clustering analysis and visualization
| Functions | Description |
|---|---|
| dist(fviz_dist, get_dist) | Enhanced Distance Matrix Computation and Visualization. |
| get_clust_tendency | Assessing Clustering Tendency. |
| fviz_nbclust(fviz_gap_stat) | Determining and Visualizing the Optimal Number of Clusters. |
| fviz_dend | Enhanced Visualization of Dendrogram |
| fviz_cluster | Visualize Clustering Results |
| fviz_mclust | Visualize Model-based Clustering Results |
| fviz_silhouette | Visualize Silhouette Information from Clustering. |
| hcut | Computes Hierarchical Clustering and Cut the Tree |
| hkmeans (hkmeans_tree, print.hkmeans) | Hierarchical k-means clustering. |
| eclust | Visual enhancement of clustering analysis |
Dimension reduction and factoextra
As depicted in the figure below, the type of analysis to be performed depends on the data set formats and structures.
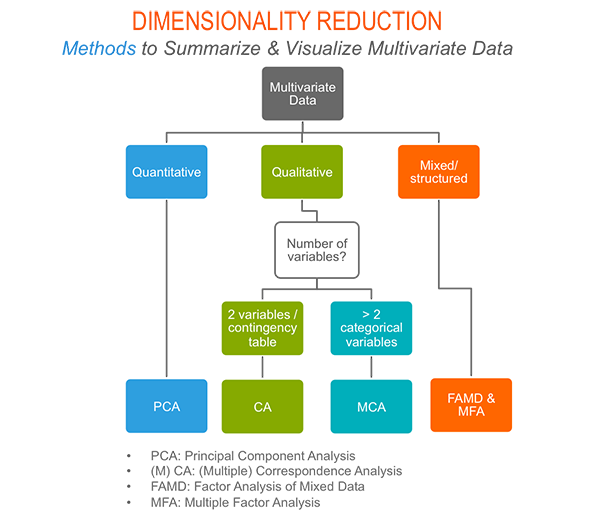
In this section we start by illustrating classical methods - such as PCA, CA and MCA - for analyzing a data set containing continuous variables, contingency table and qualitative variables, respectively.
We continue by discussing advanced methods - such as FAMD, MFA and HMFA - for analyzing a data set containing a mix of variables (qualitatives & quantitatives) organized or not into groups.
Finally, we show how to perform hierarchical clustering on principal components (HCPC), which useful for performing clustering with a data set containing only qualitative variables or with a mixed data of qualitative and quantitative variables.
Principal component analysis
- Data: decathlon2 [in factoextra package]
- PCA function: FactoMineR::PCA()
- Visualization factoextra::fviz_pca()
Read more about computing and interpreting principal component analysis at: Principal Component Analysis (PCA).
- Loading data
library("factoextra")
data("decathlon2")
df <- decathlon2[1:23, 1:10]- Principal component analysis
library("FactoMineR")
res.pca <- PCA(df, graph = FALSE)- Extract and visualize eigenvalues/variances:
# Extract eigenvalues/variances
get_eig(res.pca)## eigenvalue variance.percent cumulative.variance.percent
## Dim.1 4.1242133 41.242133 41.24213
## Dim.2 1.8385309 18.385309 59.62744
## Dim.3 1.2391403 12.391403 72.01885
## Dim.4 0.8194402 8.194402 80.21325
## Dim.5 0.7015528 7.015528 87.22878
## Dim.6 0.4228828 4.228828 91.45760
## Dim.7 0.3025817 3.025817 94.48342
## Dim.8 0.2744700 2.744700 97.22812
## Dim.9 0.1552169 1.552169 98.78029
## Dim.10 0.1219710 1.219710 100.00000# Visualize eigenvalues/variances
fviz_screeplot(res.pca, addlabels = TRUE, ylim = c(0, 50))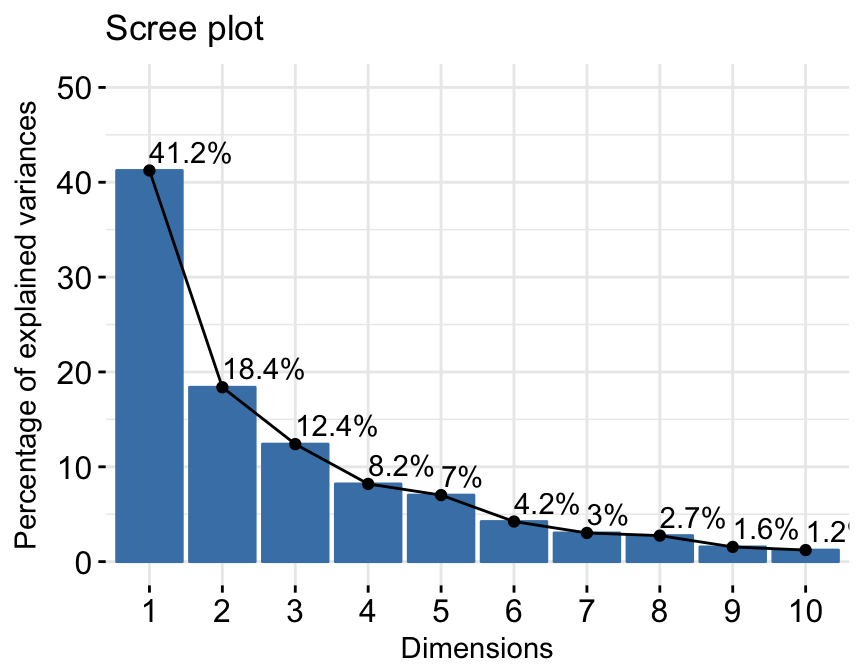
factoextra
4.Extract and visualize results for variables:
# Extract the results for variables
var <- get_pca_var(res.pca)
var## Principal Component Analysis Results for variables
## ===================================================
## Name Description
## 1 "$coord" "Coordinates for the variables"
## 2 "$cor" "Correlations between variables and dimensions"
## 3 "$cos2" "Cos2 for the variables"
## 4 "$contrib" "contributions of the variables"# Coordinates of variables
head(var$coord)## Dim.1 Dim.2 Dim.3 Dim.4 Dim.5
## X100m -0.8506257 -0.17939806 0.3015564 0.03357320 -0.1944440
## Long.jump 0.7941806 0.28085695 -0.1905465 -0.11538956 0.2331567
## Shot.put 0.7339127 0.08540412 0.5175978 0.12846837 -0.2488129
## High.jump 0.6100840 -0.46521415 0.3300852 0.14455012 0.4027002
## X400m -0.7016034 0.29017826 0.2835329 0.43082552 0.1039085
## X110m.hurdle -0.7641252 -0.02474081 0.4488873 -0.01689589 0.2242200# Contribution of variables
head(var$contrib)## Dim.1 Dim.2 Dim.3 Dim.4 Dim.5
## X100m 17.544293 1.7505098 7.338659 0.13755240 5.389252
## Long.jump 15.293168 4.2904162 2.930094 1.62485936 7.748815
## Shot.put 13.060137 0.3967224 21.620432 2.01407269 8.824401
## High.jump 9.024811 11.7715838 8.792888 2.54987951 23.115504
## X400m 11.935544 4.5799296 6.487636 22.65090599 1.539012
## X110m.hurdle 14.157544 0.0332933 16.261261 0.03483735 7.166193# Graph of variables: default plot
fviz_pca_var(res.pca, col.var = "black")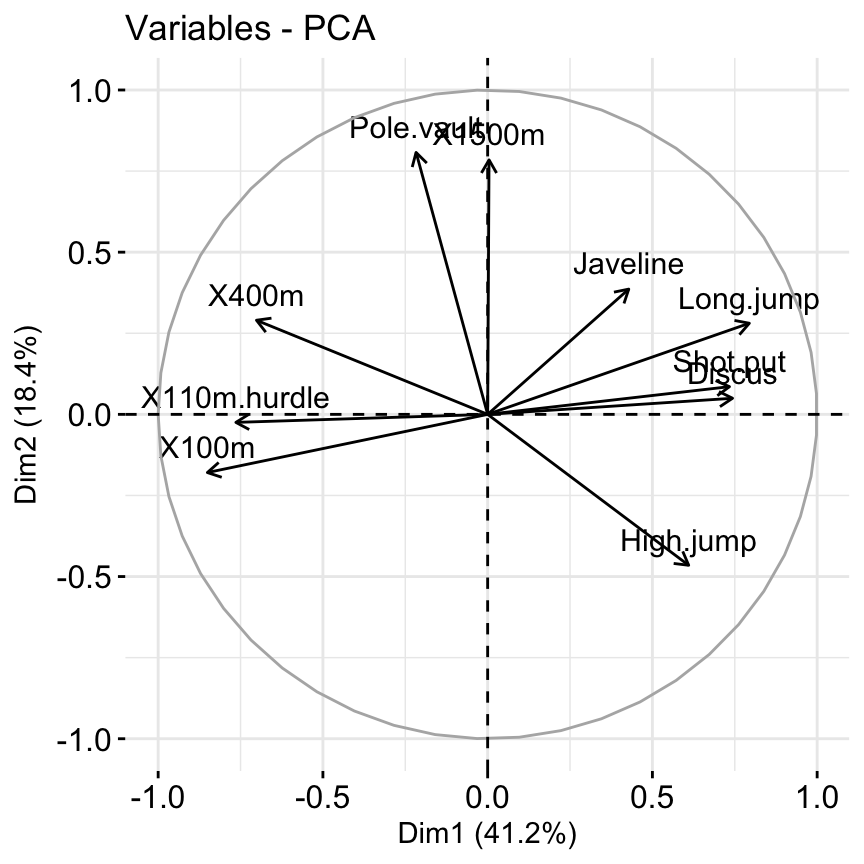
factoextra
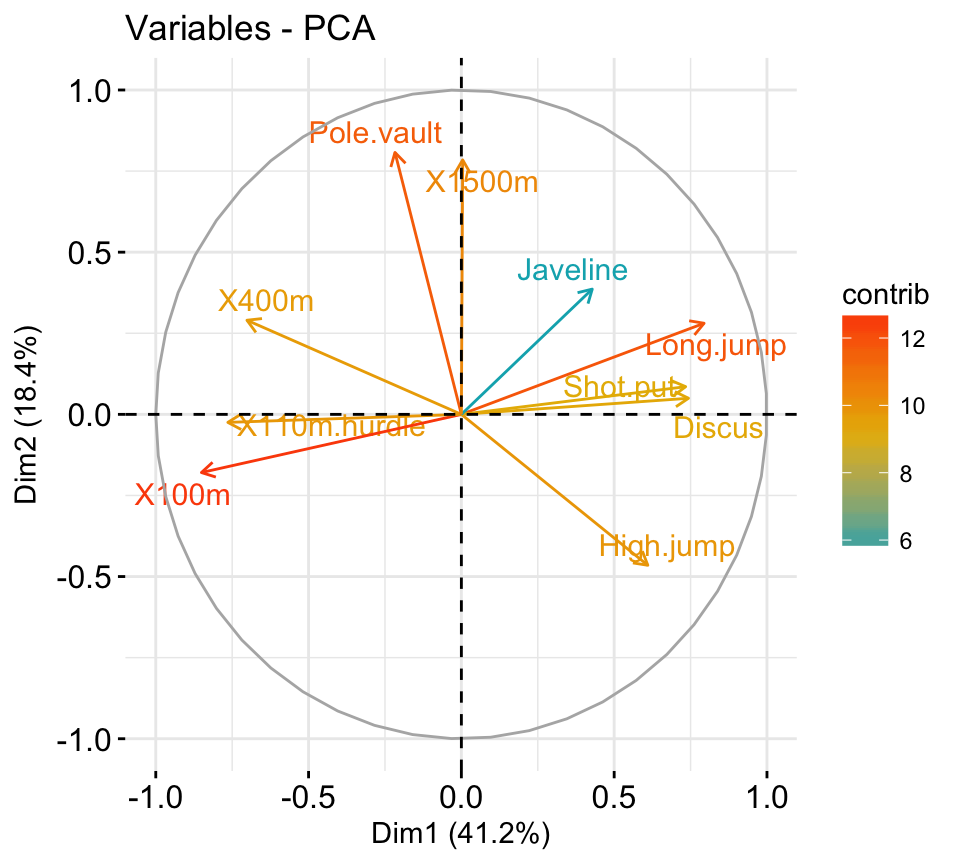
It’s possible to control variable colors using their contributions (“contrib”) to the principal axes:
# Control variable colors using their contributions
fviz_pca_var(res.pca, col.var="contrib",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE # Avoid text overlapping
)
factoextra
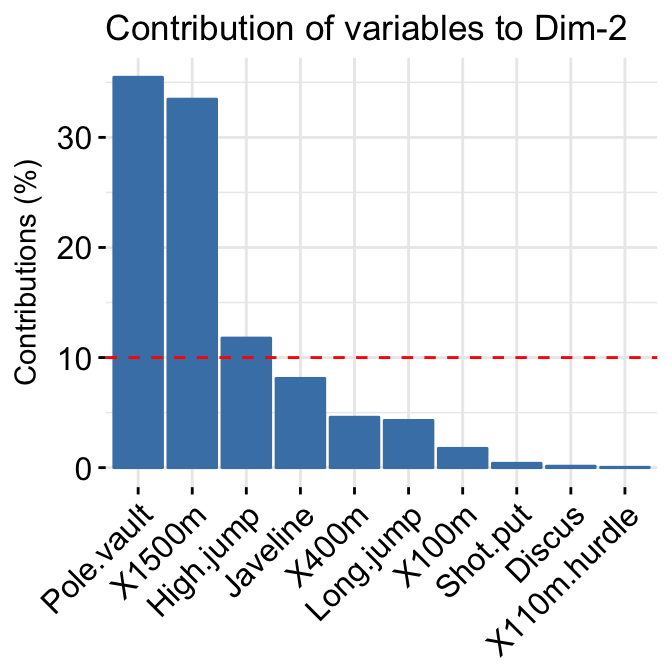
- Variable contributions to the principal axes:
# Contributions of variables to PC1
fviz_contrib(res.pca, choice = "var", axes = 1, top = 10)
# Contributions of variables to PC2
fviz_contrib(res.pca, choice = "var", axes = 2, top = 10)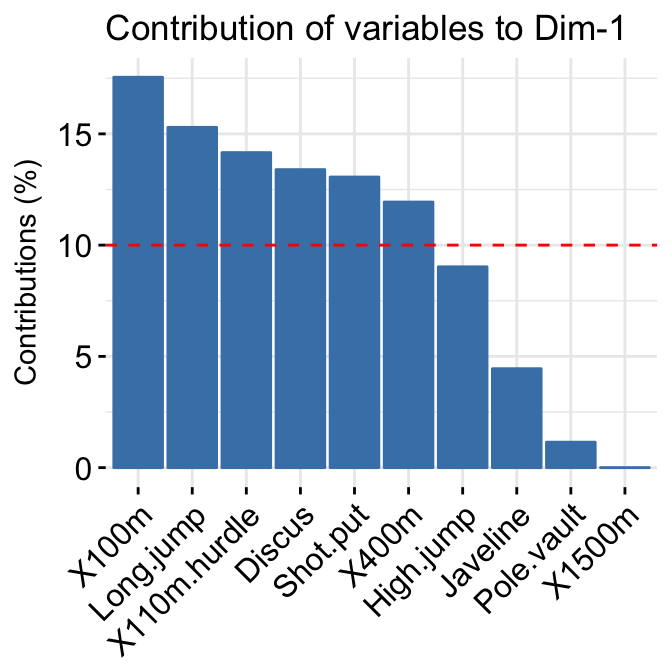
factoextra
- Extract and visualize results for individuals:
# Extract the results for individuals
ind <- get_pca_ind(res.pca)
ind## Principal Component Analysis Results for individuals
## ===================================================
## Name Description
## 1 "$coord" "Coordinates for the individuals"
## 2 "$cos2" "Cos2 for the individuals"
## 3 "$contrib" "contributions of the individuals"# Coordinates of individuals
head(ind$coord)## Dim.1 Dim.2 Dim.3 Dim.4 Dim.5
## SEBRLE 0.1955047 1.5890567 0.6424912 0.08389652 1.16829387
## CLAY 0.8078795 2.4748137 -1.3873827 1.29838232 -0.82498206
## BERNARD -1.3591340 1.6480950 0.2005584 -1.96409420 0.08419345
## YURKOV -0.8889532 -0.4426067 2.5295843 0.71290837 0.40782264
## ZSIVOCZKY -0.1081216 -2.0688377 -1.3342591 -0.10152796 -0.20145217
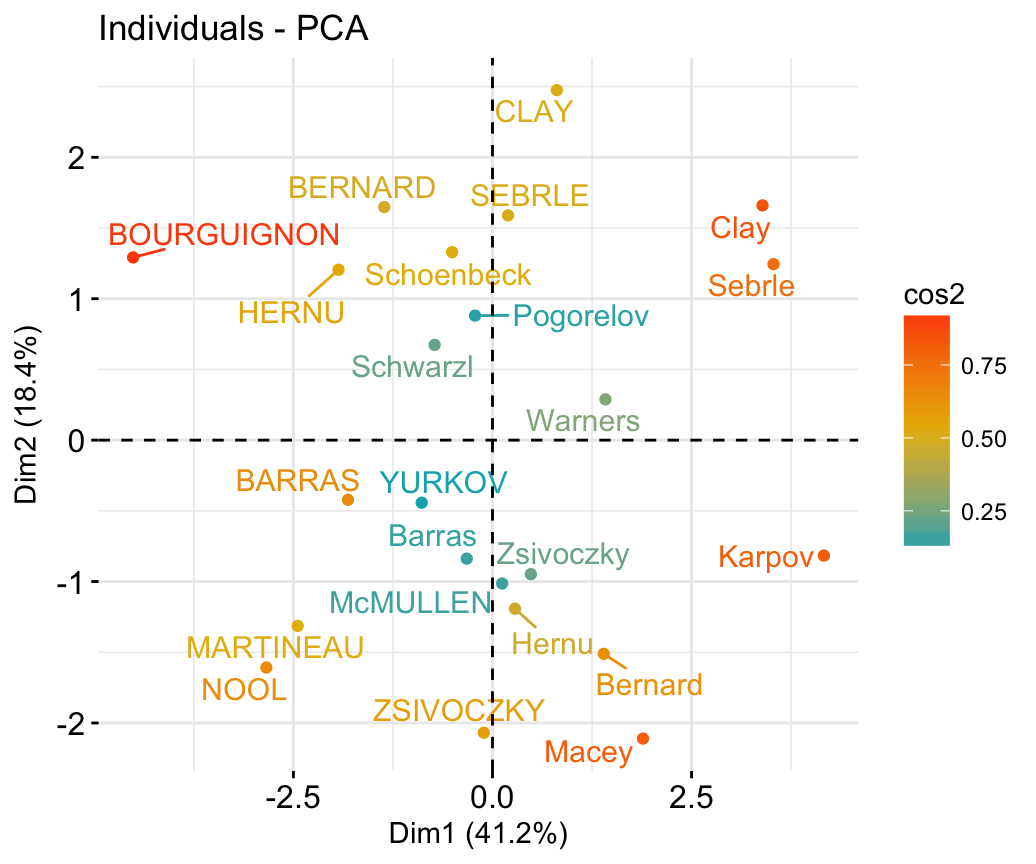
## McMULLEN 0.1212195 -1.0139102 -0.8625170 1.34164291 1.62151286# Graph of individuals
# 1. Use repel = TRUE to avoid overplotting
# 2. Control automatically the color of individuals using the cos2
# cos2 = the quality of the individuals on the factor map
# Use points only
# 3. Use gradient color
fviz_pca_ind(res.pca, col.ind = "cos2",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE # Avoid text overlapping (slow if many points)
)
factoextra
# Biplot of individuals and variables
fviz_pca_biplot(res.pca, repel = TRUE)
factoextra
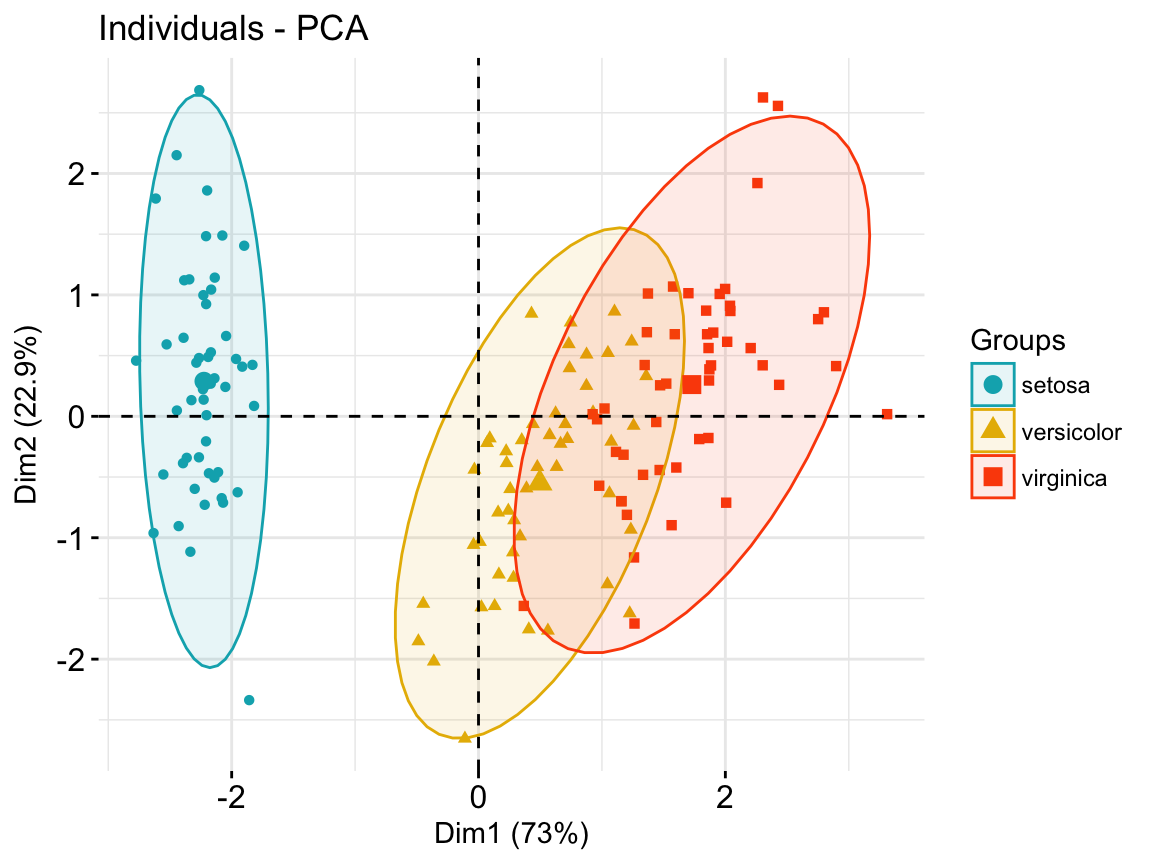
- Color individuals by groups:
# Compute PCA on the iris data set
# The variable Species (index = 5) is removed
# before PCA analysis
iris.pca <- PCA(iris[,-5], graph = FALSE)
# Visualize
# Use habillage to specify groups for coloring
fviz_pca_ind(iris.pca,
label = "none", # hide individual labels
habillage = iris$Species, # color by groups
palette = c("#00AFBB", "#E7B800", "#FC4E07"),
addEllipses = TRUE # Concentration ellipses
)
factoextra
Correspondence analysis
- Data: housetasks [in factoextra]
- CA function FactoMineR::CA()
- Visualize with factoextra::fviz_ca()
Read more about computing and interpreting correspondence analysis at: Correspondence Analysis (CA).
- Compute CA:
# Loading data
data("housetasks")
# Computing CA
library("FactoMineR")
res.ca <- CA(housetasks, graph = FALSE)- Extract results for row/column variables:
# Result for row variables
get_ca_row(res.ca)
# Result for column variables
get_ca_col(res.ca)- Biplot of rows and columns
fviz_ca_biplot(res.ca, repel = TRUE)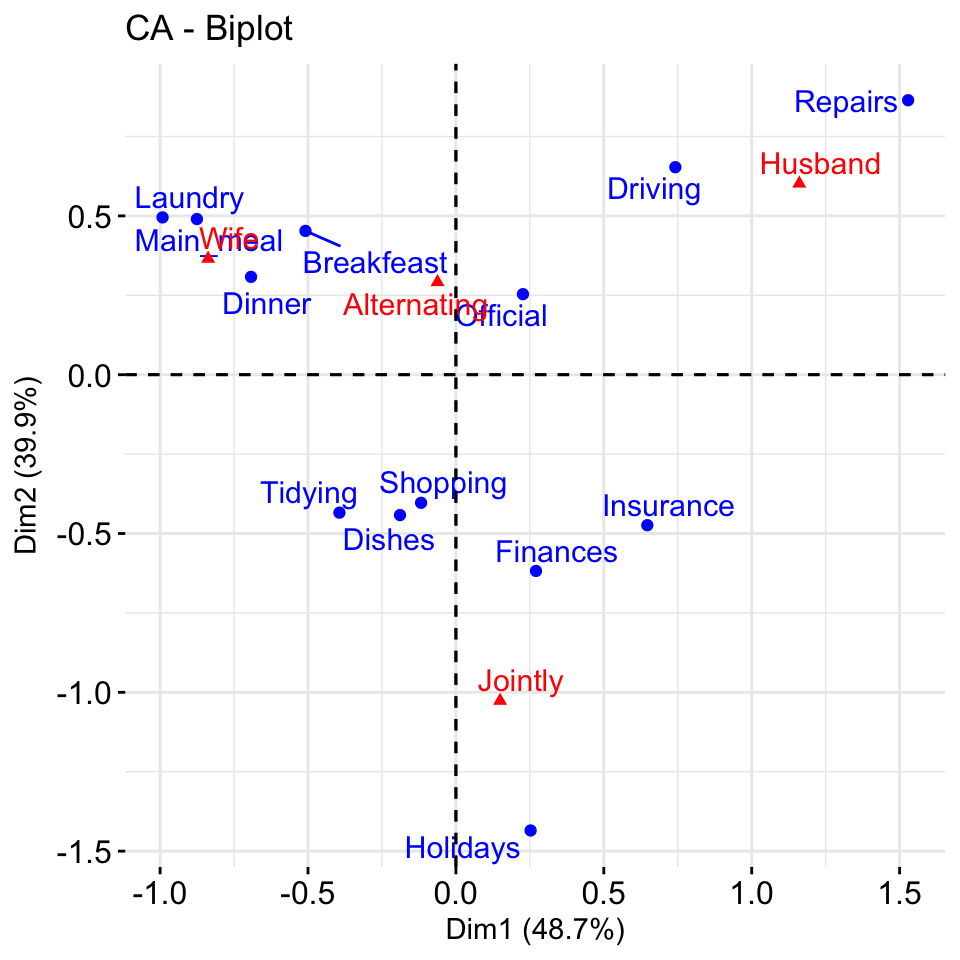
factoextra
To visualize only row points or column points, type this:
# Graph of row points
fviz_ca_row(res.ca, repel = TRUE)
# Graph of column points
fviz_ca_col(res.ca)
# Visualize row contributions on axes 1
fviz_contrib(res.ca, choice ="row", axes = 1)
# Visualize column contributions on axes 1
fviz_contrib(res.ca, choice ="col", axes = 1)Multiple correspondence analysis
- Data: poison [in factoextra]
- MCA function FactoMineR::MCA()
- Visualization factoextra::fviz_mca()
Read more about computing and interpreting multiple correspondence analysis at: Multiple Correspondence Analysis (MCA).
- Computing MCA:
library(FactoMineR)
data(poison)
res.mca <- MCA(poison, quanti.sup = 1:2,
quali.sup = 3:4, graph=FALSE)- Extract results for variables and individuals:
# Extract the results for variable categories
get_mca_var(res.mca)
# Extract the results for individuals
get_mca_ind(res.mca)- Contribution of variables and individuals to the principal axes:
# Visualize variable categorie contributions on axes 1
fviz_contrib(res.mca, choice ="var", axes = 1)
# Visualize individual contributions on axes 1
# select the top 20
fviz_contrib(res.mca, choice ="ind", axes = 1, top = 20)- Graph of individuals
# Color by groups
# Add concentration ellipses
# Use repel = TRUE to avoid overplotting
grp <- as.factor(poison[, "Vomiting"])
fviz_mca_ind(res.mca, habillage = grp,
addEllipses = TRUE, repel = TRUE)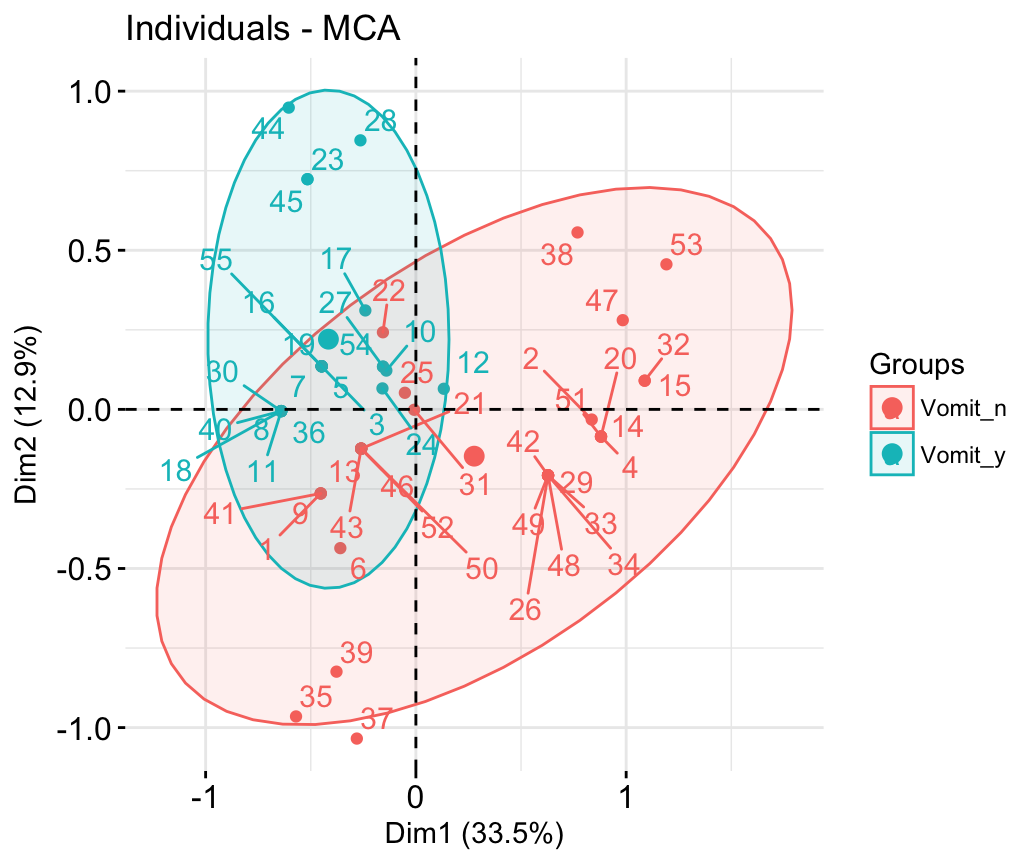
factoextra
- Graph of variable categories:
fviz_mca_var(res.mca, repel = TRUE)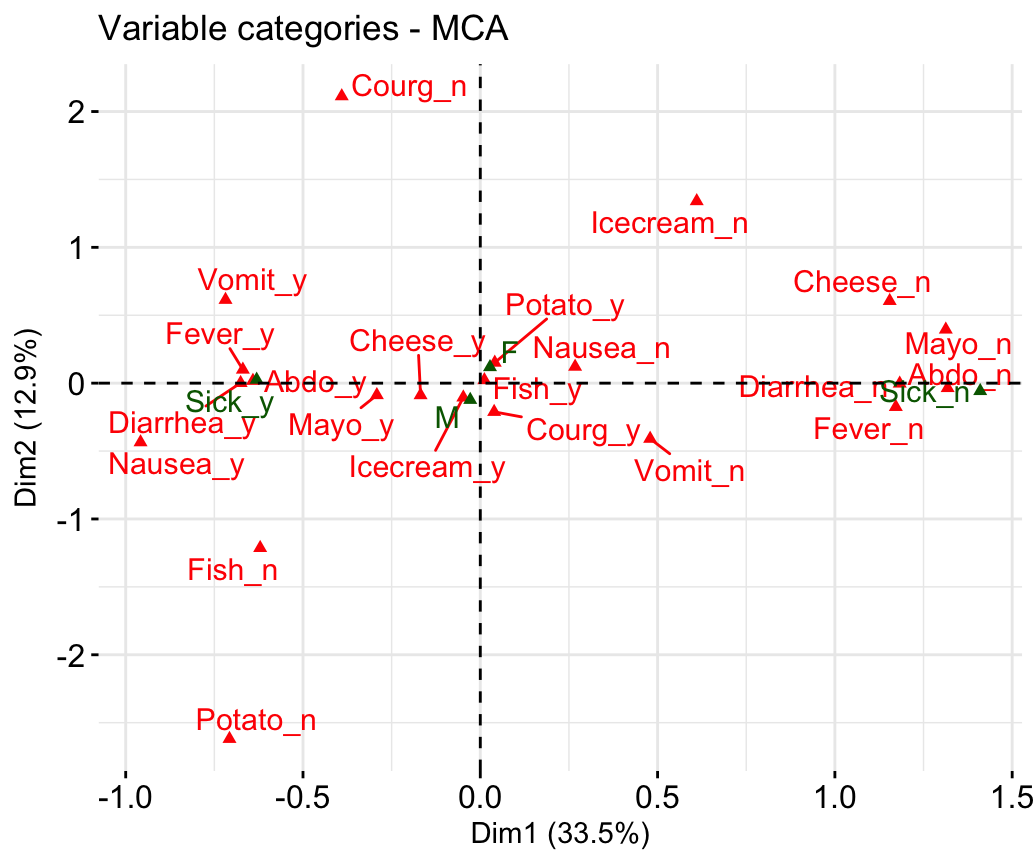
factoextra
- Biplot of individuals and variables:
fviz_mca_biplot(res.mca, repel = TRUE)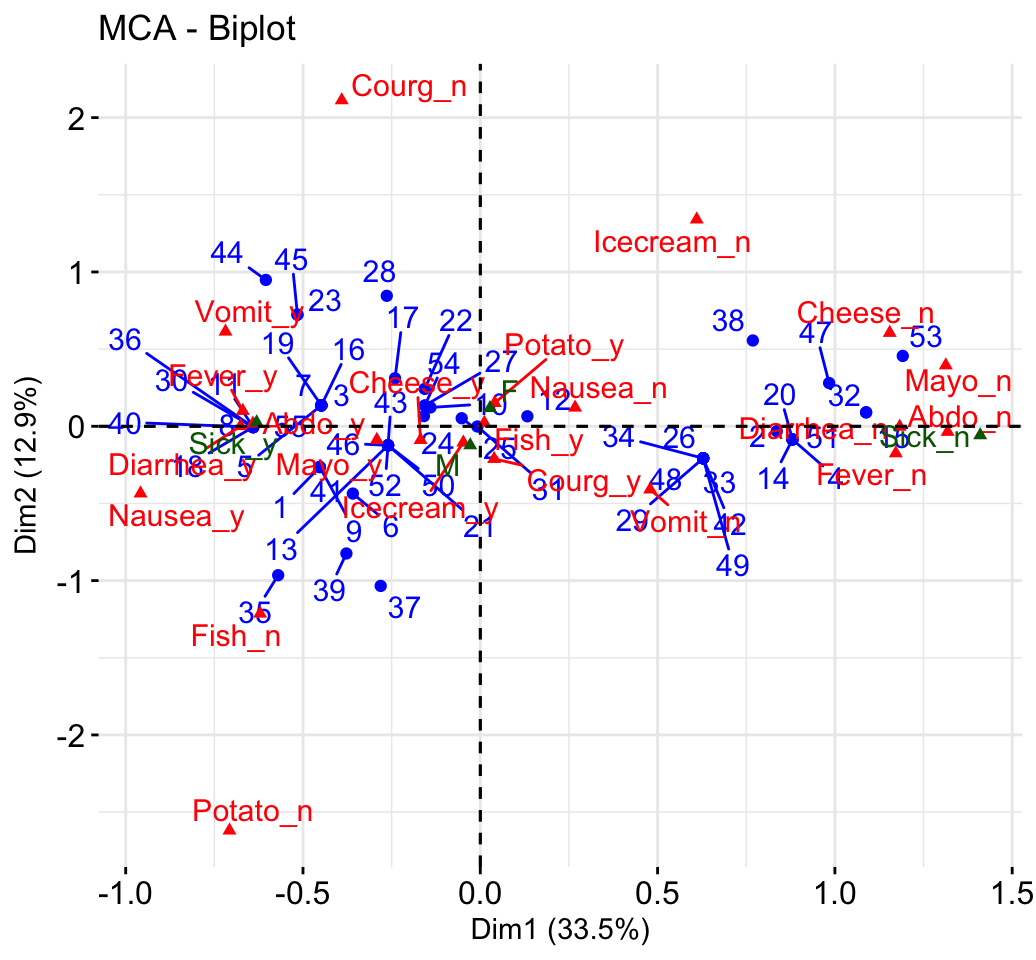
factoextra
Advanced methods
The factoextra R package has also functions that support the visualization of advanced methods such:
- Factor Analysis of Mixed Data (FAMD): : FAMD Examples
- Multiple Factor Analysis (MFA): MFA Examples
- Hierarchical Multiple Factor Analysis (HMFA): HMFA Examples
- Hierachical Clustering on Principal Components (HCPC)
Cluster analysis and factoextra
To learn more about cluster analysis, you can refer to the book available at: Practical Guide to Cluster Analysis in R

The main parts of the book include:
- distance measures,
- partitioning clustering,
- hierarchical clustering,
- cluster validation methods, as well as,
- advanced clustering methods such as fuzzy clustering, density-based clustering and model-based clustering.
The book presents the basic principles of these tasks and provide many examples in R. It offers solid guidance in data mining for students and researchers.
Partitioning clustering
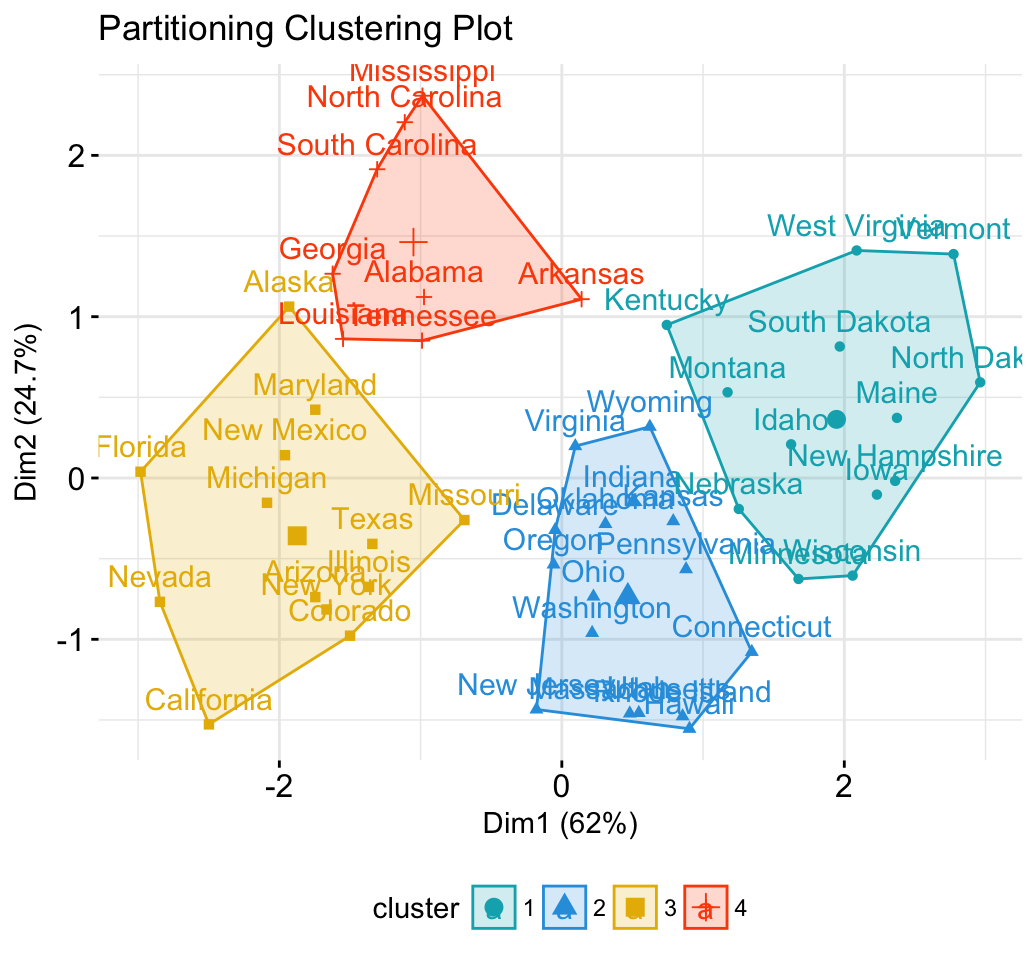
# 1. Loading and preparing data
data("USArrests")
df <- scale(USArrests)
# 2. Compute k-means
set.seed(123)
km.res <- kmeans(scale(USArrests), 4, nstart = 25)
# 3. Visualize
library("factoextra")
fviz_cluster(km.res, data = df,
palette = c("#00AFBB","#2E9FDF", "#E7B800", "#FC4E07"),
ggtheme = theme_minimal(),
main = "Partitioning Clustering Plot"
)
factoextra
Hierarchical clustering
library("factoextra")
# Compute hierarchical clustering and cut into 4 clusters
res <- hcut(USArrests, k = 4, stand = TRUE)
# Visualize
fviz_dend(res, rect = TRUE, cex = 0.5,
k_colors = c("#00AFBB","#2E9FDF", "#E7B800", "#FC4E07"))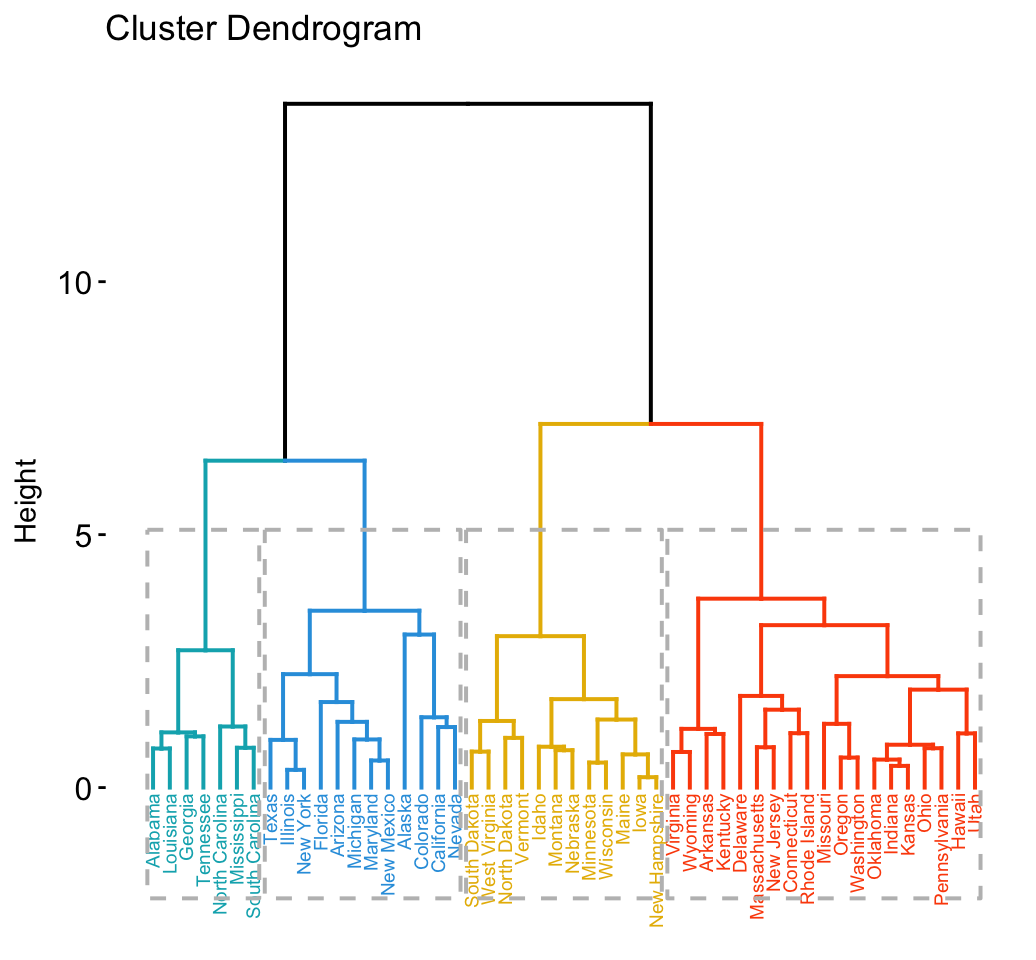
factoextra
Determine the optimal number of clusters
# Optimal number of clusters for k-means
library("factoextra")
my_data <- scale(USArrests)
fviz_nbclust(my_data, kmeans, method = "gap_stat")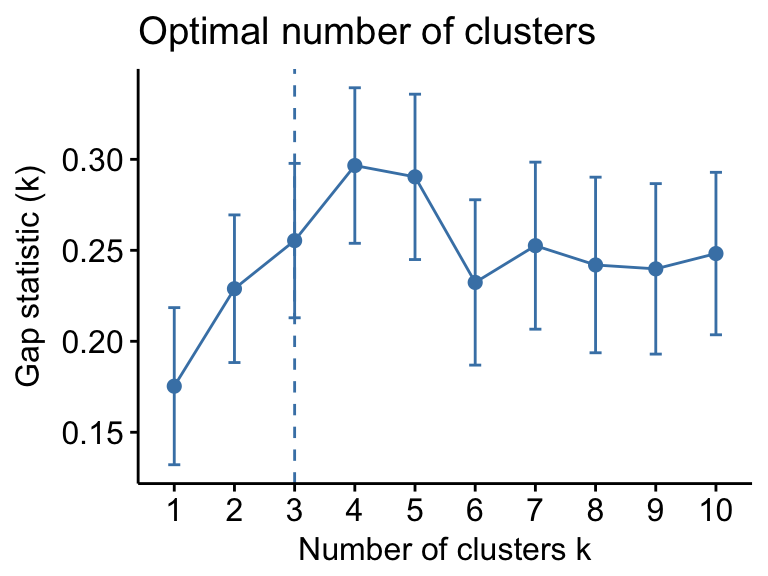
factoextra
Acknoweledgment
I would like to thank Fabian Mundt for his active contributions to factoextra.
We sincerely thank all developers for their efforts behind the packages that factoextra depends on, namely, ggplot2 (Hadley Wickham, Springer-Verlag New York, 2009), FactoMineR (Sebastien Le et al., Journal of Statistical Software, 2008), dendextend (Tal Galili, Bioinformatics, 2015), cluster (Martin Maechler et al., 2016) and more …..
References
- H. Wickham (2009). ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York.
- Maechler, M., Rousseeuw, P., Struyf, A., Hubert, M., Hornik, K.(2016). cluster: Cluster Analysis Basics and Extensions. R package version 2.0.5.
- Sebastien Le, Julie Josse, Francois Husson (2008). FactoMineR: An R Package for Multivariate Analysis. Journal of Statistical Software, 25(1), 1-18. 10.18637/jss.v025.i01
- Tal Galili (2015). dendextend: an R package for visualizing, adjusting, and comparing trees of hierarchical clustering. Bioinformatics. DOI: 10.1093/bioinformatics/btv428
Infos
This analysis has been performed using R software (ver. 3.3.2) and factoextra (ver. 1.0.4.999)
Show me some love with the like buttons below... Thank you and please don't forget to share and comment below!!
Montrez-moi un peu d'amour avec les like ci-dessous ... Merci et n'oubliez pas, s'il vous plaît, de partager et de commenter ci-dessous!
Recommended for You!





Recommended for you
This section contains the best data science and self-development resources to help you on your path.
Books - Data Science
Our Books
- Practical Guide to Cluster Analysis in R by A. Kassambara (Datanovia)
- Practical Guide To Principal Component Methods in R by A. Kassambara (Datanovia)
- Machine Learning Essentials: Practical Guide in R by A. Kassambara (Datanovia)
- R Graphics Essentials for Great Data Visualization by A. Kassambara (Datanovia)
- GGPlot2 Essentials for Great Data Visualization in R by A. Kassambara (Datanovia)
- Network Analysis and Visualization in R by A. Kassambara (Datanovia)
- Practical Statistics in R for Comparing Groups: Numerical Variables by A. Kassambara (Datanovia)
- Inter-Rater Reliability Essentials: Practical Guide in R by A. Kassambara (Datanovia)
Others
- R for Data Science: Import, Tidy, Transform, Visualize, and Model Data by Hadley Wickham & Garrett Grolemund
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems by Aurelien Géron
- Practical Statistics for Data Scientists: 50 Essential Concepts by Peter Bruce & Andrew Bruce
- Hands-On Programming with R: Write Your Own Functions And Simulations by Garrett Grolemund & Hadley Wickham
- An Introduction to Statistical Learning: with Applications in R by Gareth James et al.
- Deep Learning with R by François Chollet & J.J. Allaire
- Deep Learning with Python by François Chollet
Click to follow us on Facebook :
Comment this article by clicking on "Discussion" button (top-right position of this page)
Articles contained by this category :
Eigenvalues: Quick data visualization with factoextra - R software and data mining
Explore the outputs of a principal component analysis - R software and data mining
factoextra: Reduce overplotting of points and labels - R software and data mining
facto_summarize - Subset and summarize the output of factor analyses - R software and data mining
fviz_ca: Quick Correspondence Analysis data visualization using factoextra - R software and data mining
fviz_contrib - Quick visualization of row/column contributions - R software and data mining
fviz_cos2: Quick visualization of the quality of representation of rows/columns - R software and data mining
fviz_mca: Quick Multiple Correspondence Analysis data visualization - R software and data mining
fviz_pca: Quick Principal Component Analysis data visualization - R software and data mining
get_ca: Extract the results for rows/columns in Correspondence Analysis - R software and data mining
get_mca: Extract the results for individuals/variables in Multiple Correspondence Analysis
get_pca: Extract the results for individuals/variables in Principal Component Analysis - R software and data mining