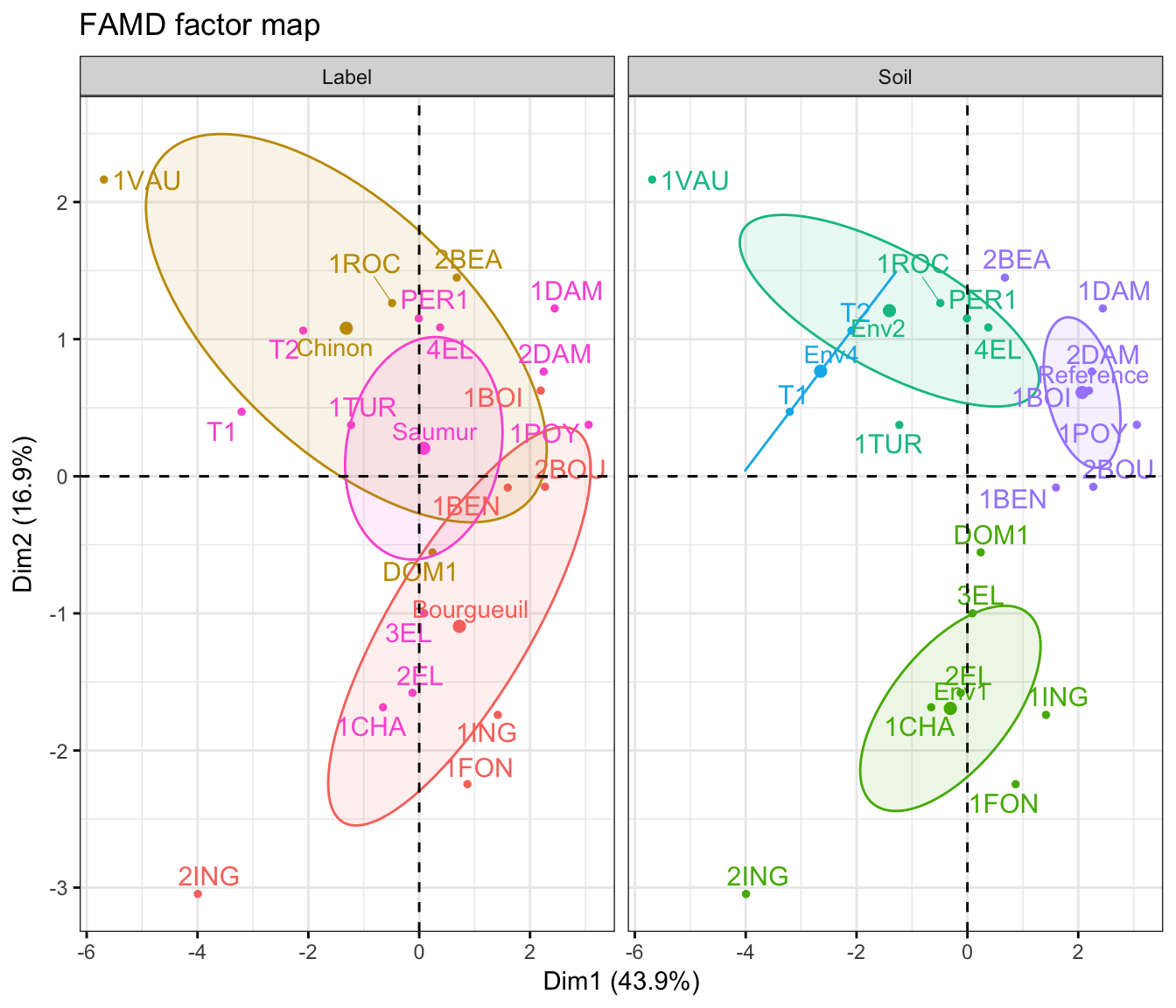
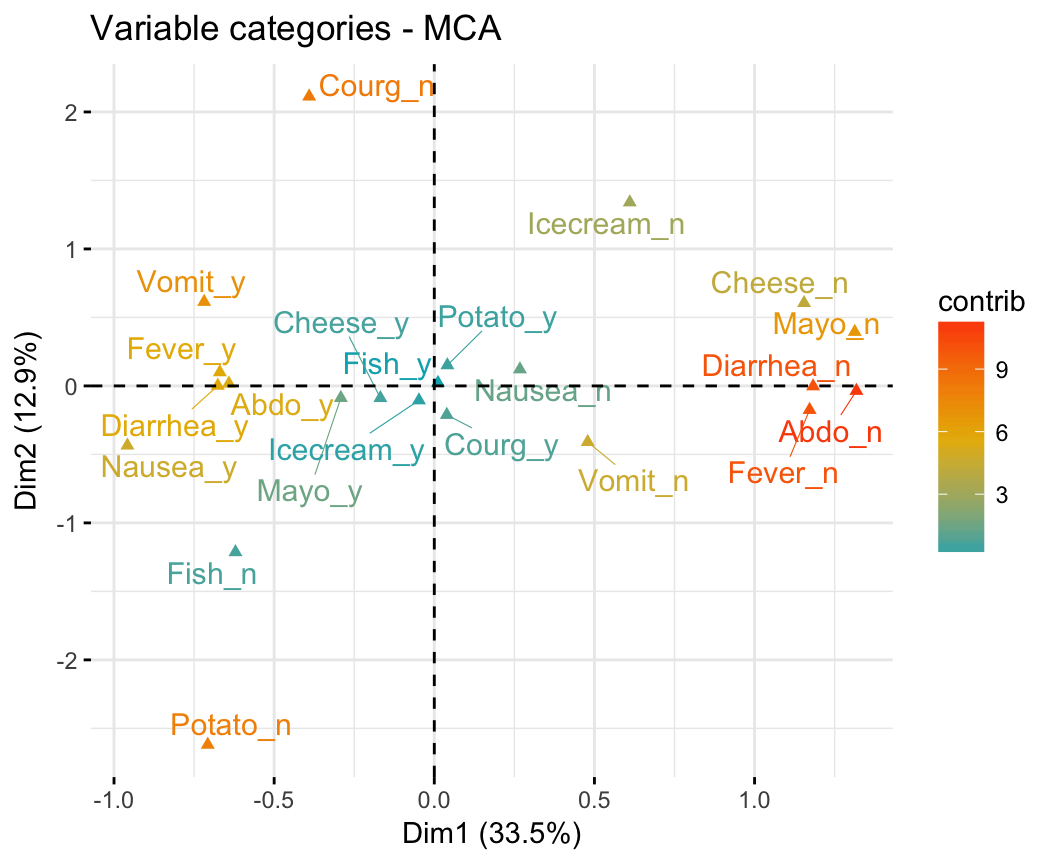
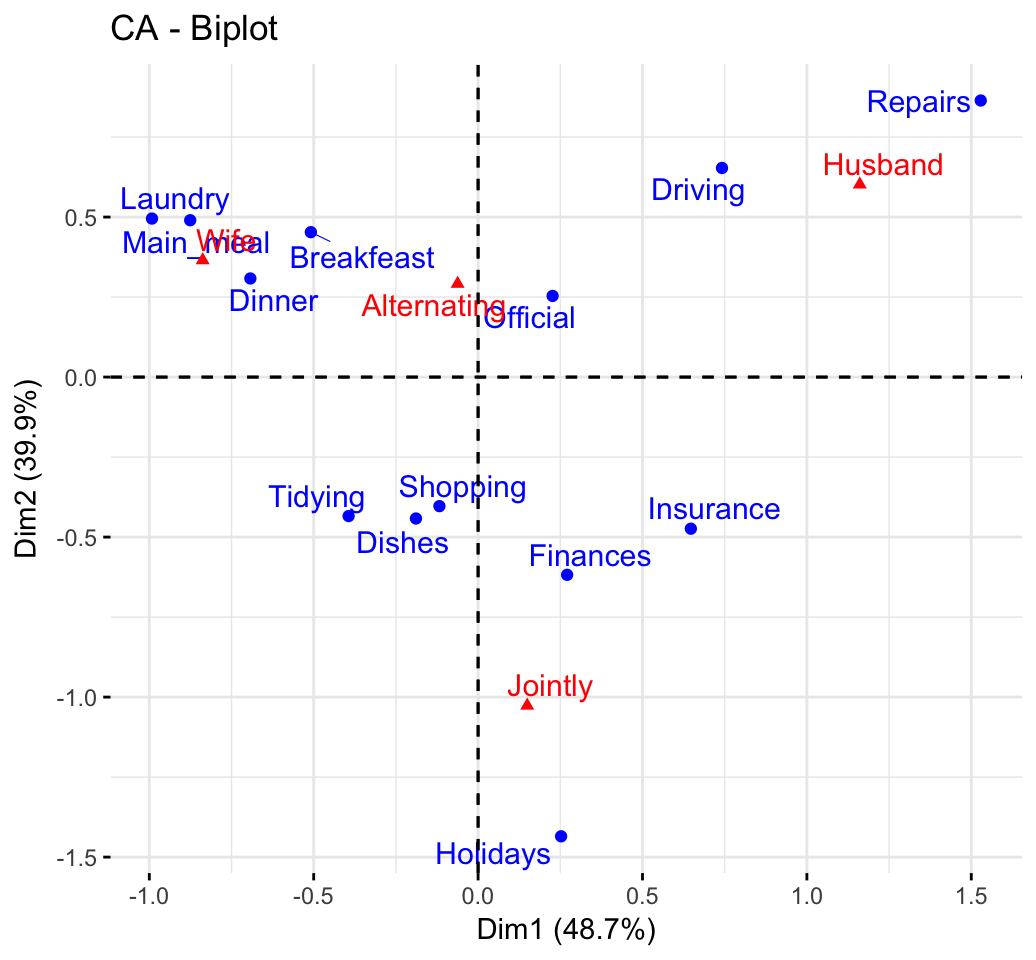
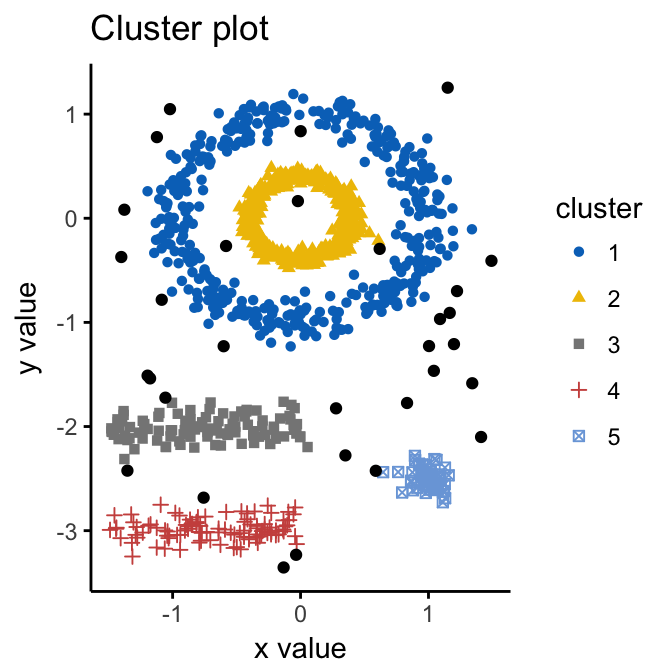
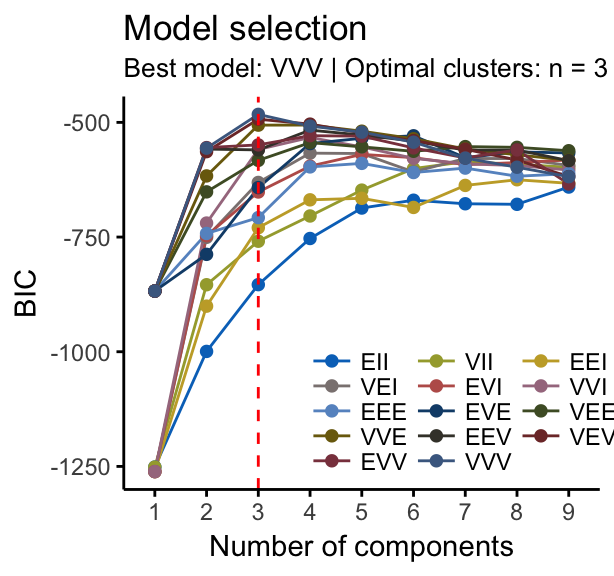
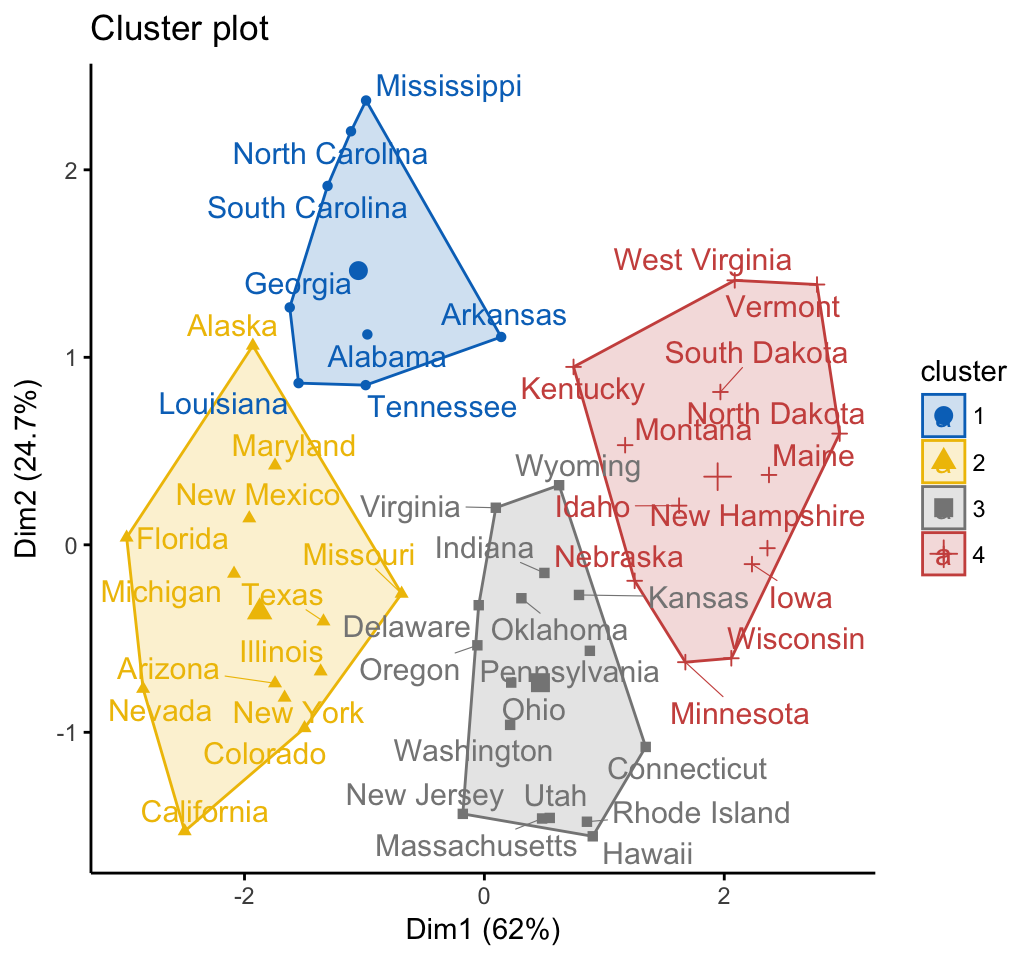
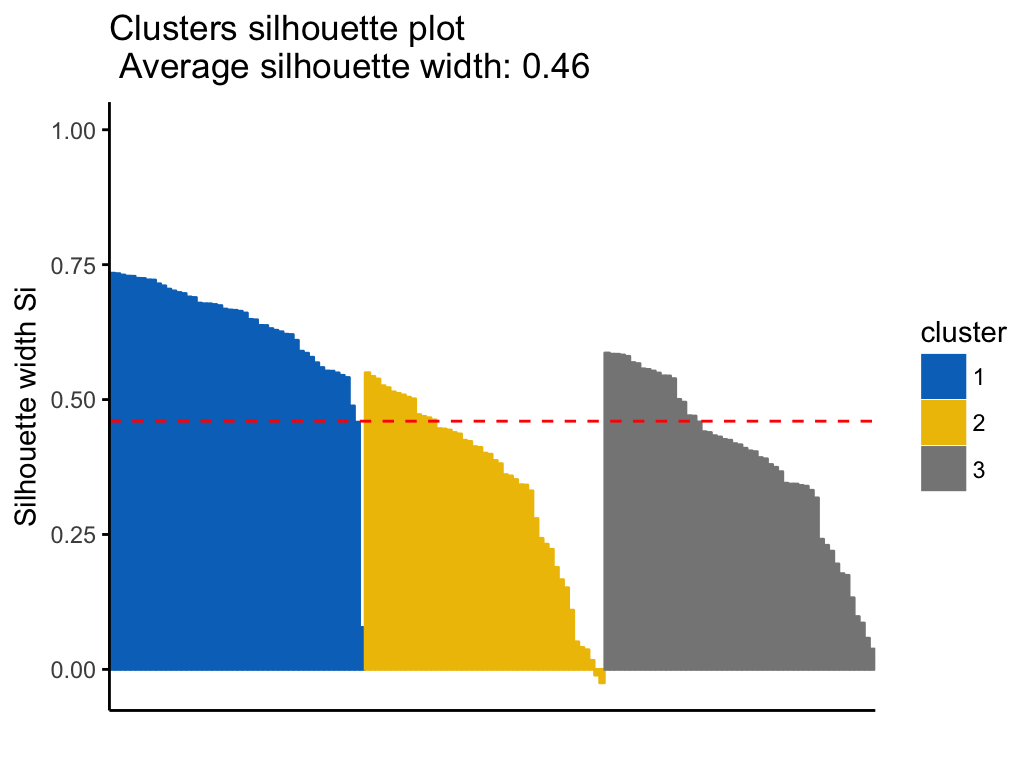
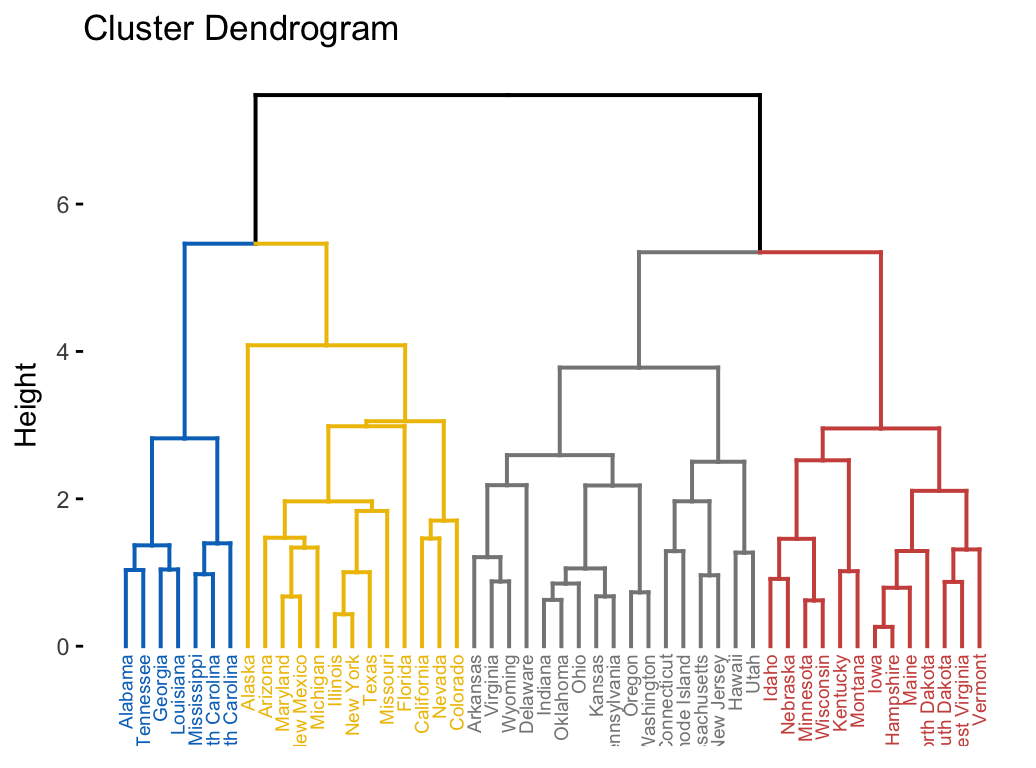
HCPC - Hierarchical Clustering on Principal Components: Essentials
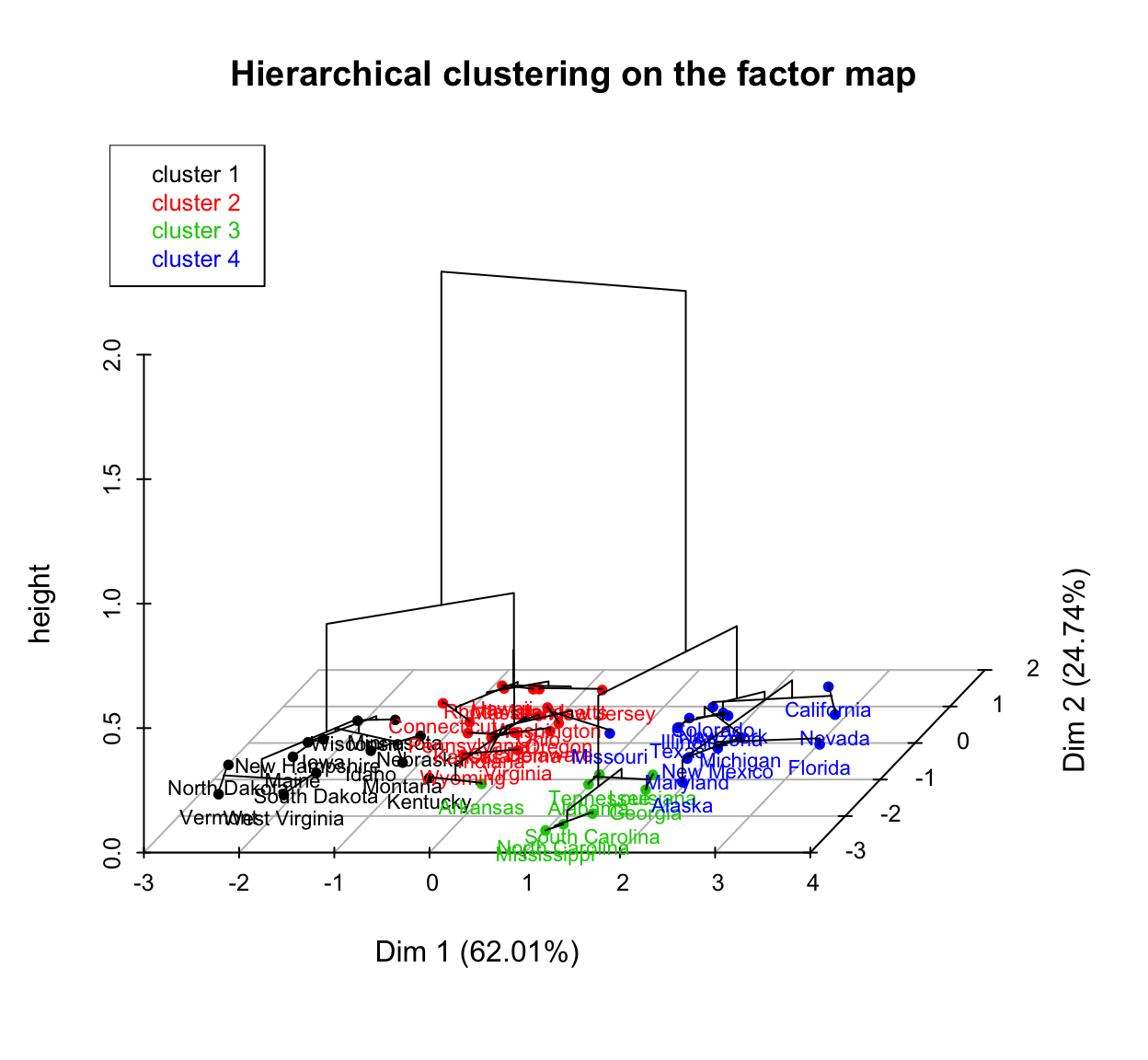
Clustering is one of the important data mining methods for discovering knowledge in multivariate data sets. The goal is to identify groups (i.e. clusters) of similar objects within a data... [Read more]