
Divisive Hierarchical Clustering Essentials
By
kassambara,
The
in Hierarchical Clustering Essentials
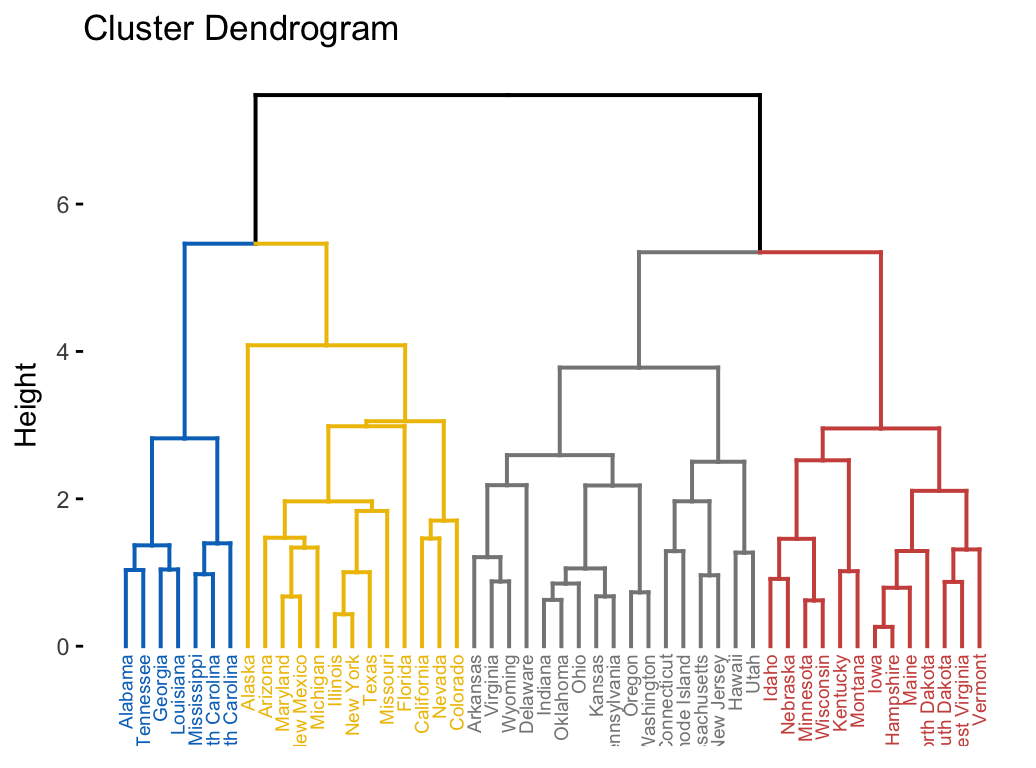
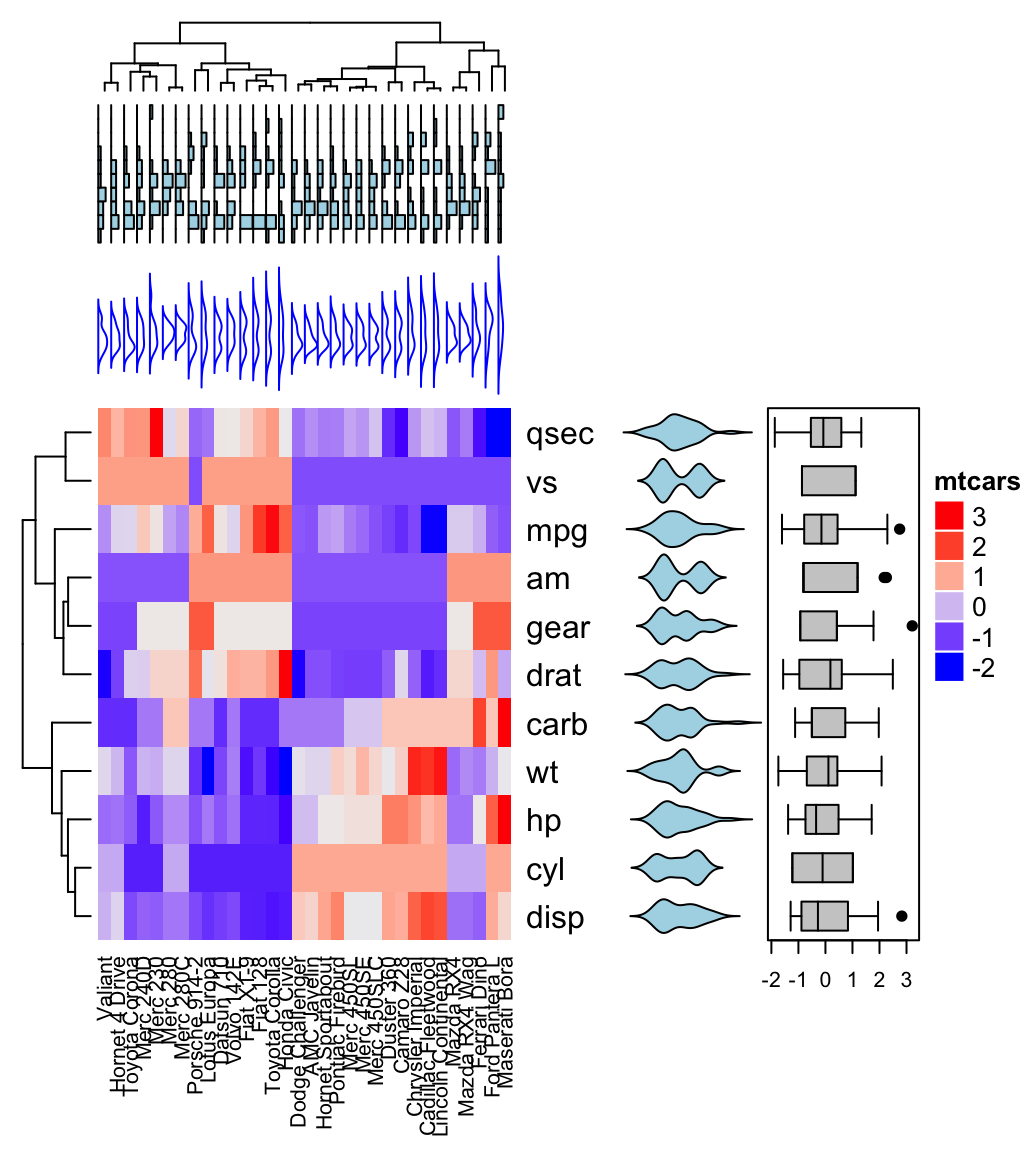
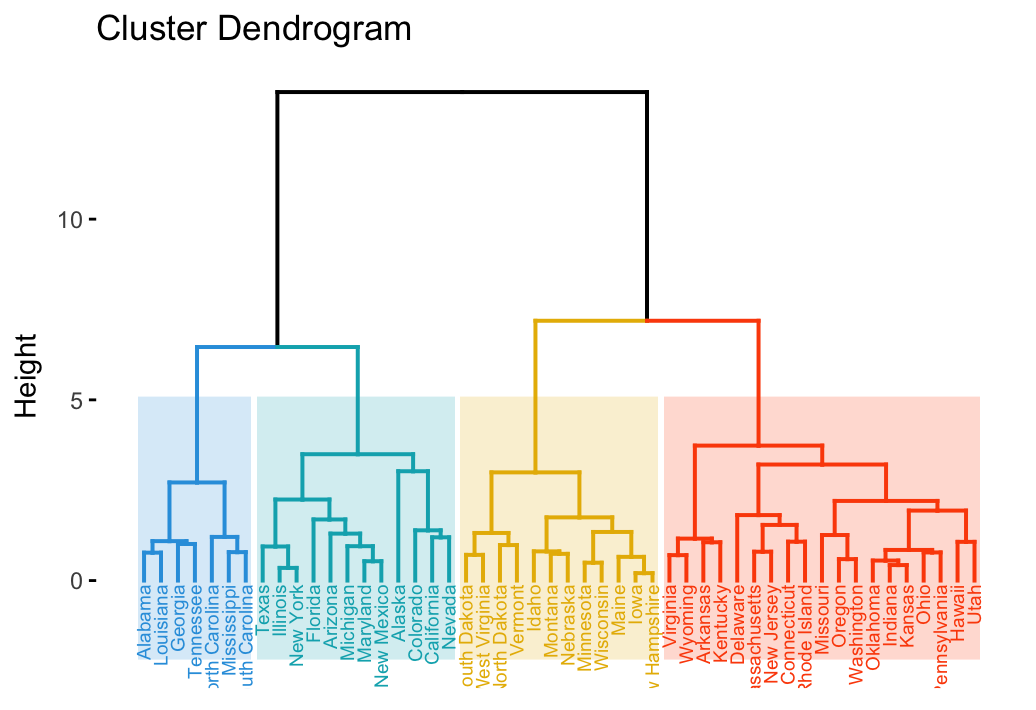
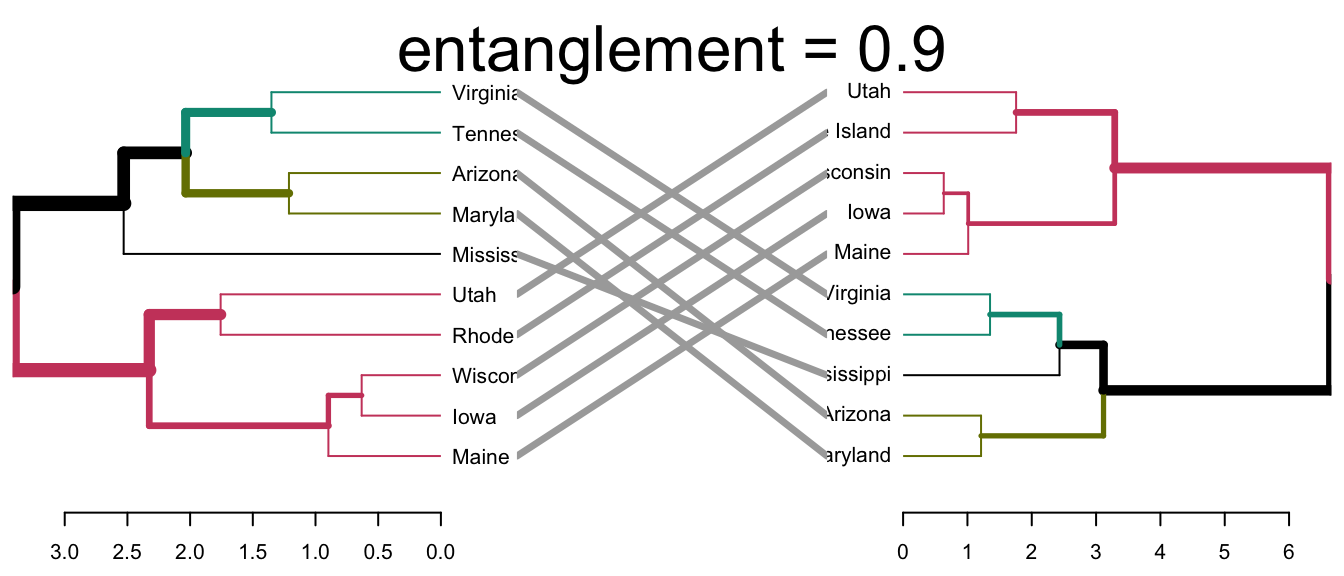
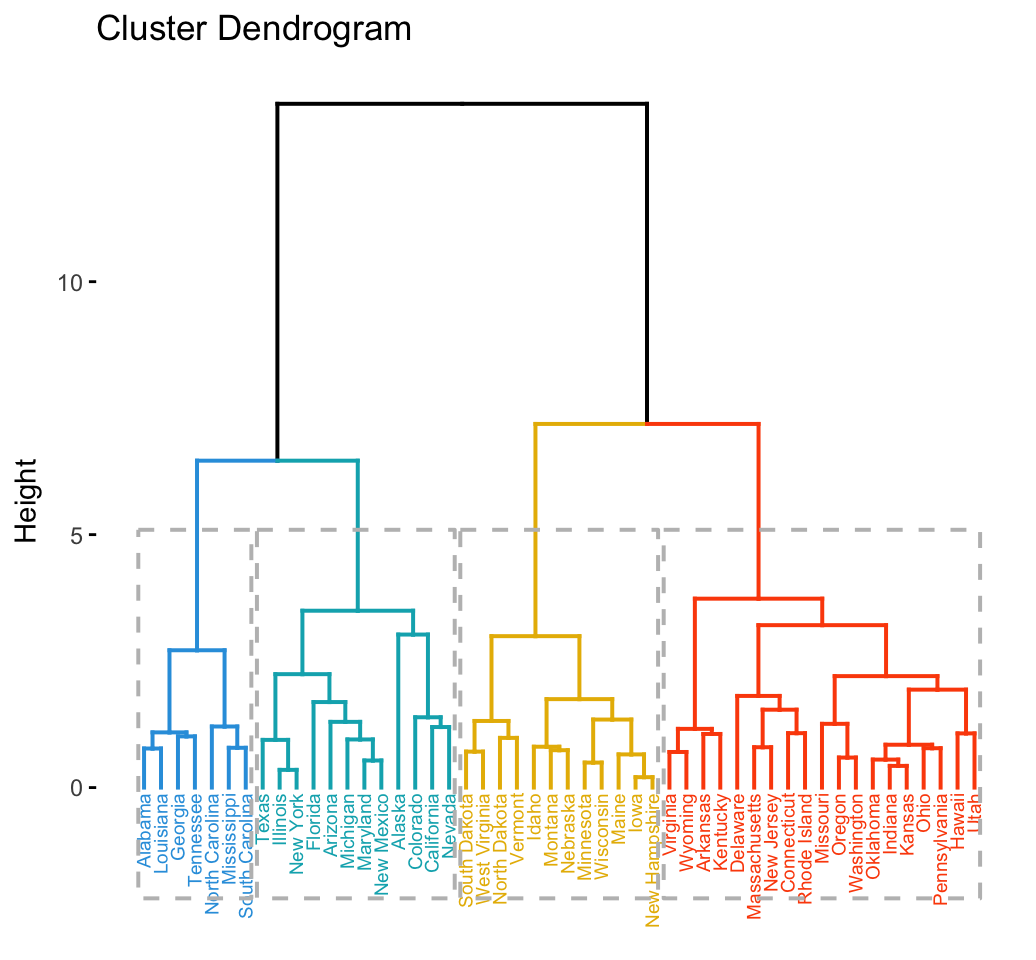
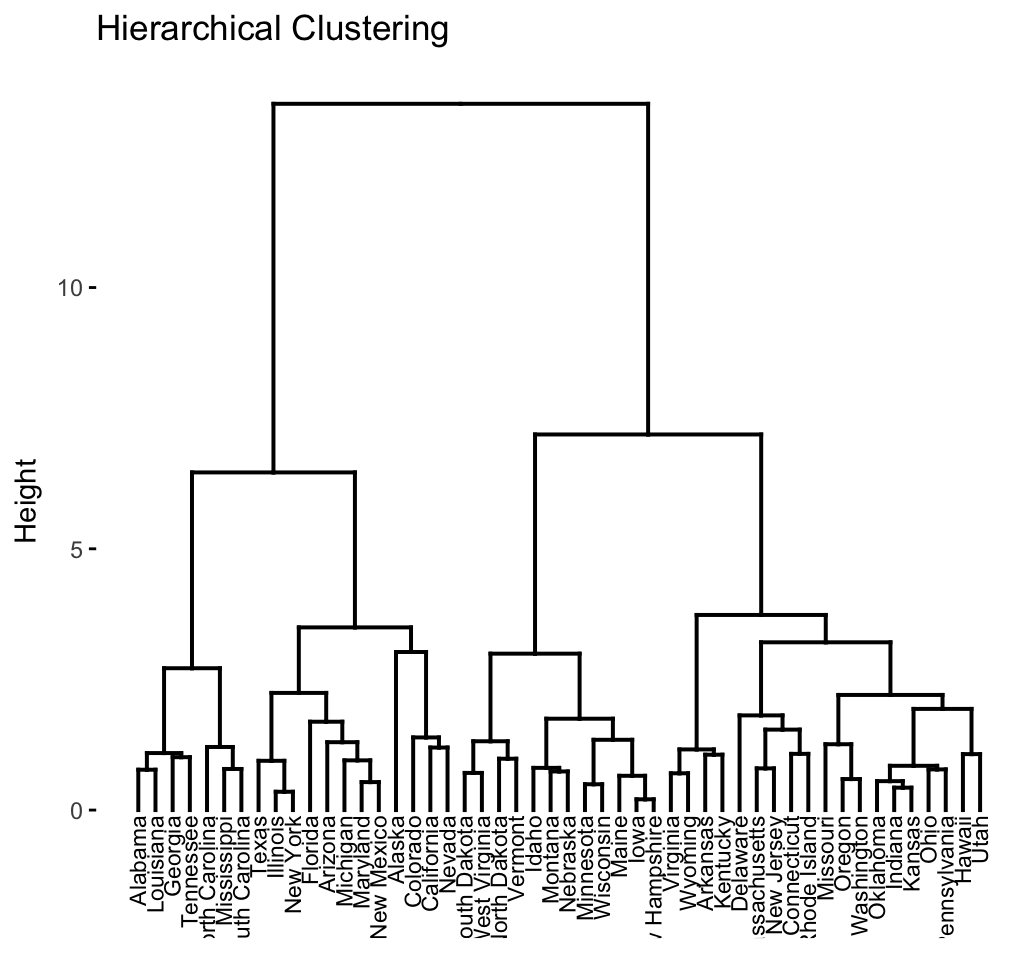
The divisive hierarchical clustering, also known as DIANA (DIvisive ANAlysis) is the inverse of agglomerative clustering (Chapter @ref(agglomerative-clustering)).
This article introduces the... [Read more]