Contents
Assessing Clustering Tendency
- Required R packages
- Data preparation
- Visual inspection of the data
- Why assessing clustering tendency?
- Methods for assessing clustering tendency
- Statistical methods
- Visual methods
Determining The Optimal Number Of Clusters
- Elbow method
- Average silhouette method
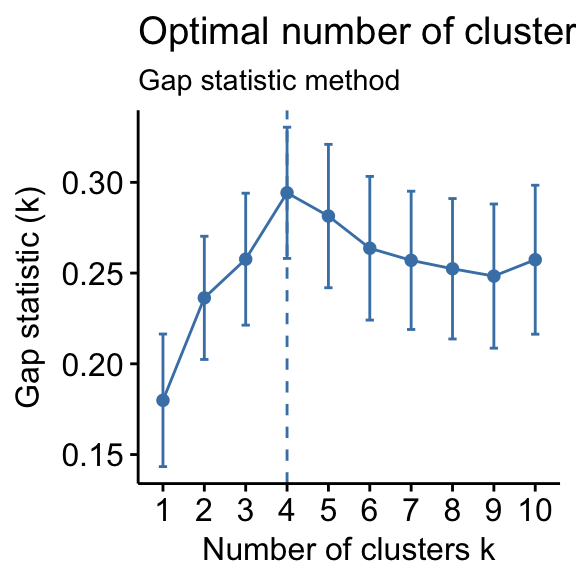
- Gap statistic method
- Computing the number of clusters using R
- Required R packages
- Data preparation
- fviz_nbclust() function: Elbow, Silhouhette and Gap statistic methods
- NbClust() function: 30 indices for choosing the best number of clusters
Cluster Validation Statistics
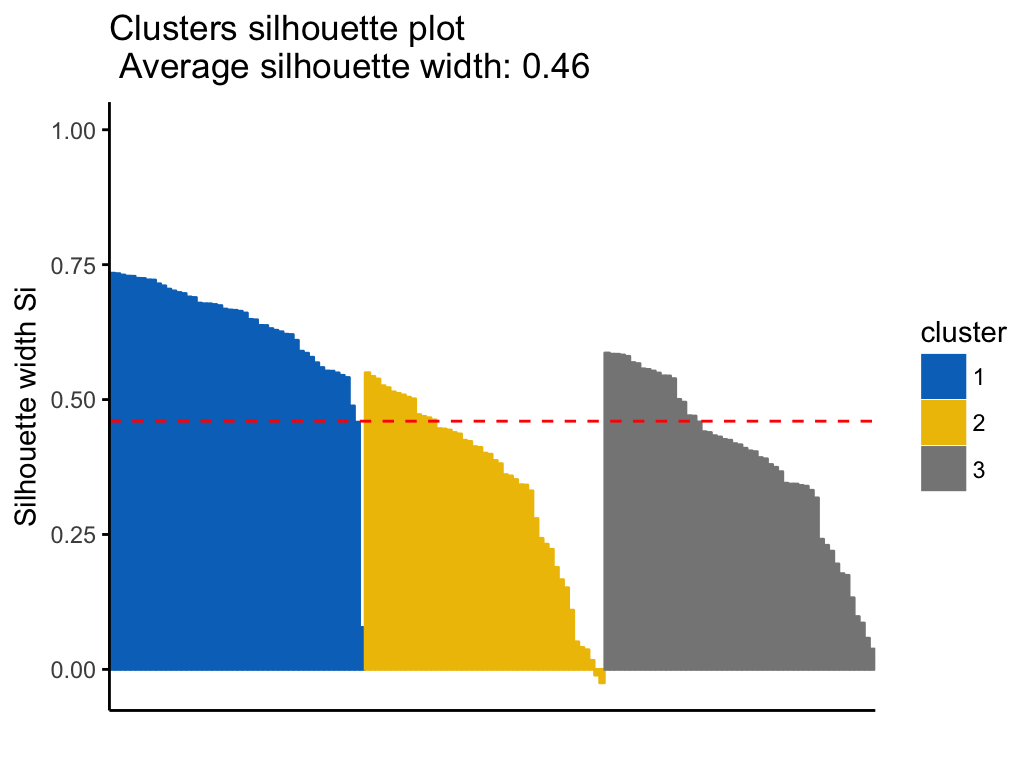
- Internal measures for cluster validation
- Silhouette coefficient
- Dunn index
- External measures for clustering validation
- Computing cluster validation statistics in R
- Required R packages
- Data preparation
- Clustering analysis
- Cluster validation
- External clustering validation
Choosing the Best Clustering Algorithms
- Measures for comparing clustering algorithms
- Compare clustering algorithms in R
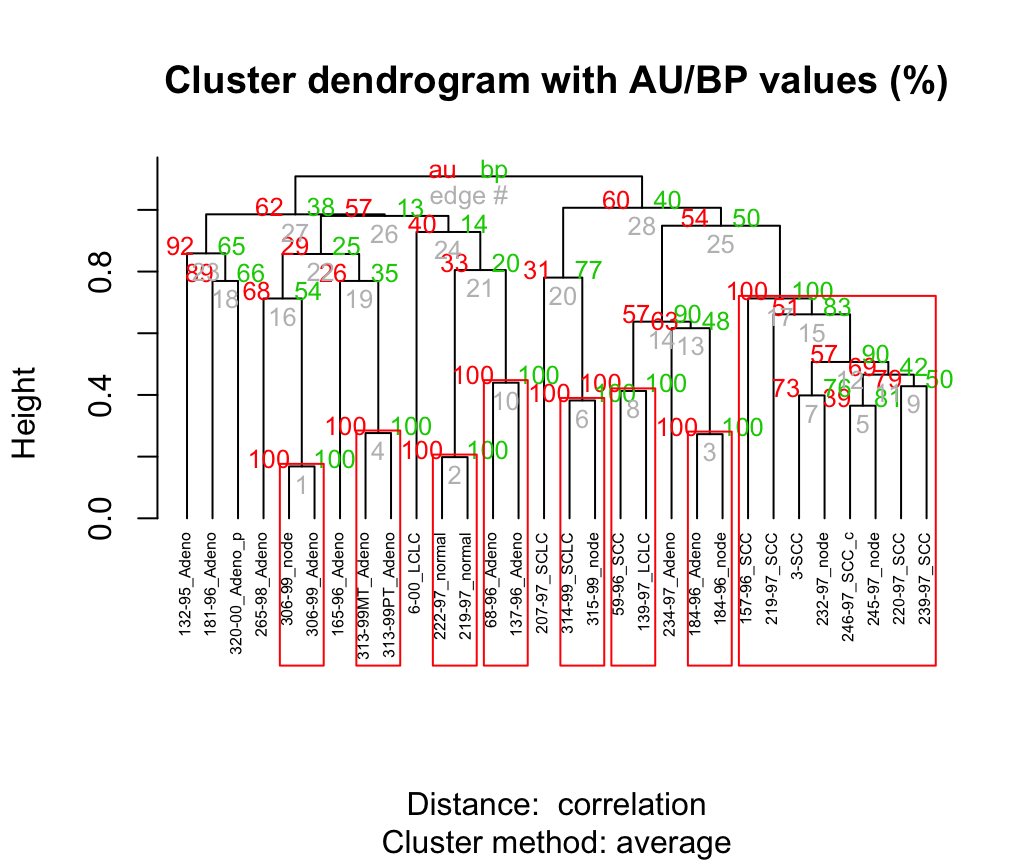
Computing P-value for Hierarchical Clustering
- Description of pvclust() function
- Usage of pvclust() function