


Perfect Scatter Plots with Correlation and Marginal Histograms
Scatter plots are used to display the relationship between two variables x and y. In this article, we’ll start by showing how to create beautiful scatter plots in R. We’ll use helper functions in the ggpubr R package to display automatically the correlation coefficient and the significance level on the plot. We’ll also describe how to color points by groups and to add concentration ellipses around each group. Additionally, we’ll show how to create bubble charts, as well as, how to add marginal plots (histogram, density or boxplot) to a scatter plot.
![]()
Contents:
Prerequisites
Required R package
You need to install the R package ggpubr (version >= 0.1.3), to easily create ggplot2-based publication ready plots.
We recommend to install the latest developmental version from GitHub as follow:
if(!require(devtools)) install.packages("devtools")
devtools::install_github("kassambara/ggpubr")If installation from Github failed, then try to install from CRAN as follow:
install.packages("ggpubr")Load ggpubr:
library(ggpubr)The following R functions will be used:
- ggscatter()[in ggpubr]: plot scatter plots
- stat_cor()[in ggpubr]: Add correlation coefficients and significance levels
Demo data sets
Data: mtcars data sets.
# Load data
data("mtcars")
df <- mtcars
# Convert cyl as a grouping variable
df$cyl <- as.factor(df$cyl)
# Inspect the data
head(df[, c("wt", "mpg", "cyl", "qsec")])## wt mpg cyl qsec
## Mazda RX4 2.62 21.0 6 16.5
## Mazda RX4 Wag 2.88 21.0 6 17.0
## Datsun 710 2.32 22.8 4 18.6
## Hornet 4 Drive 3.21 21.4 6 19.4
## Hornet Sportabout 3.44 18.7 8 17.0
## Valiant 3.46 18.1 6 20.2Basic plots
ggscatter(df, x = "wt", y = "mpg",
add = "reg.line", # Add regression line
conf.int = TRUE, # Add confidence interval
add.params = list(color = "blue",
fill = "lightgray")
)+
stat_cor(method = "pearson", label.x = 3, label.y = 30) # Add correlation coefficient
You can change the point shape, by specifying the argument shape, for example:
ggscatter(df, x = "wt", y = "mpg",
shape = 18)To see the different point shapes commonly used in R, type this:
show_point_shapes()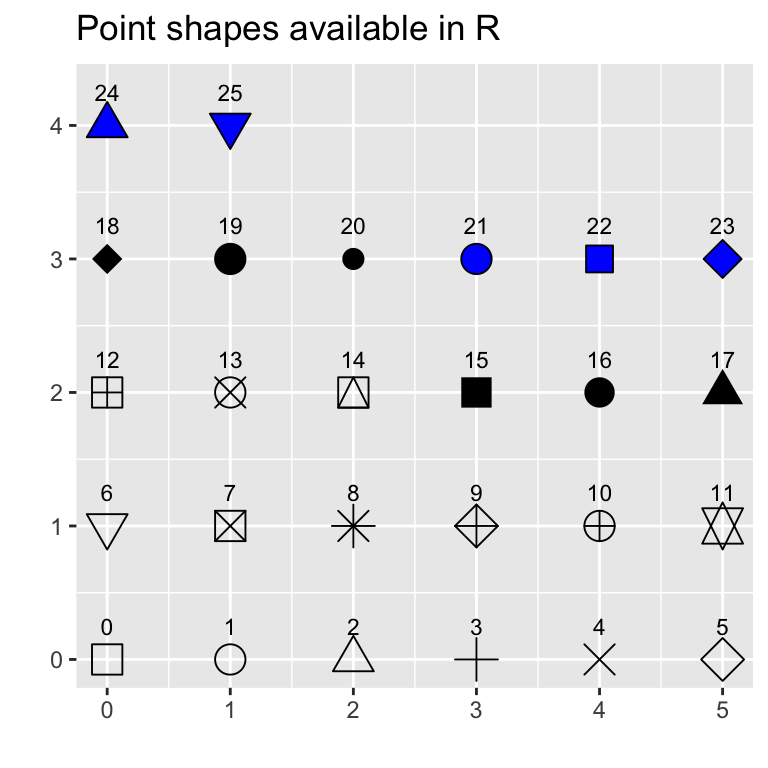
Color by groups
Grouping variable: cyl. To add a correlation coefficient per group, specify the grouping variable using the mapping function aes() as follow.
ggscatter(df, x = "wt", y = "mpg",
add = "reg.line", # Add regression line
conf.int = TRUE, # Add confidence interval
color = "cyl", palette = "jco", # Color by groups "cyl"
shape = "cyl" # Change point shape by groups "cyl"
)+
stat_cor(aes(color = cyl), label.x = 3) # Add correlation coefficient
# Extending the regression line --> fullrange = TRUE
# Add marginal rug (marginal density) ---> rug = TRUE
ggscatter(df, x = "wt", y = "mpg",
add = "reg.line", # Add regression line
color = "cyl", palette = "jco", # Color by groups "cyl"
shape = "cyl", # Change point shape by groups "cyl"
fullrange = TRUE, # Extending the regression line
rug = TRUE # Add marginal rug
)+
stat_cor(aes(color = cyl), label.x = 3) # Add correlation coefficient
Add concentration ellipses
Main arguments:
- ellipse = TRUE: Draw ellipses around groups.
- ellipse.level: The size of the concentration ellipse in normal probability. Default is 0.95.
- ellipse.type: Ellipse types. Possible values are ‘convex’, ‘confidence’ or types supported by ggplot2::stat_ellipse including one of c(“t”, “norm”, “euclid”). Default is “norm”.
ggscatter(df, x = "wt", y = "mpg",
color = "cyl", palette = "jco",
shape = "cyl",
ellipse = TRUE)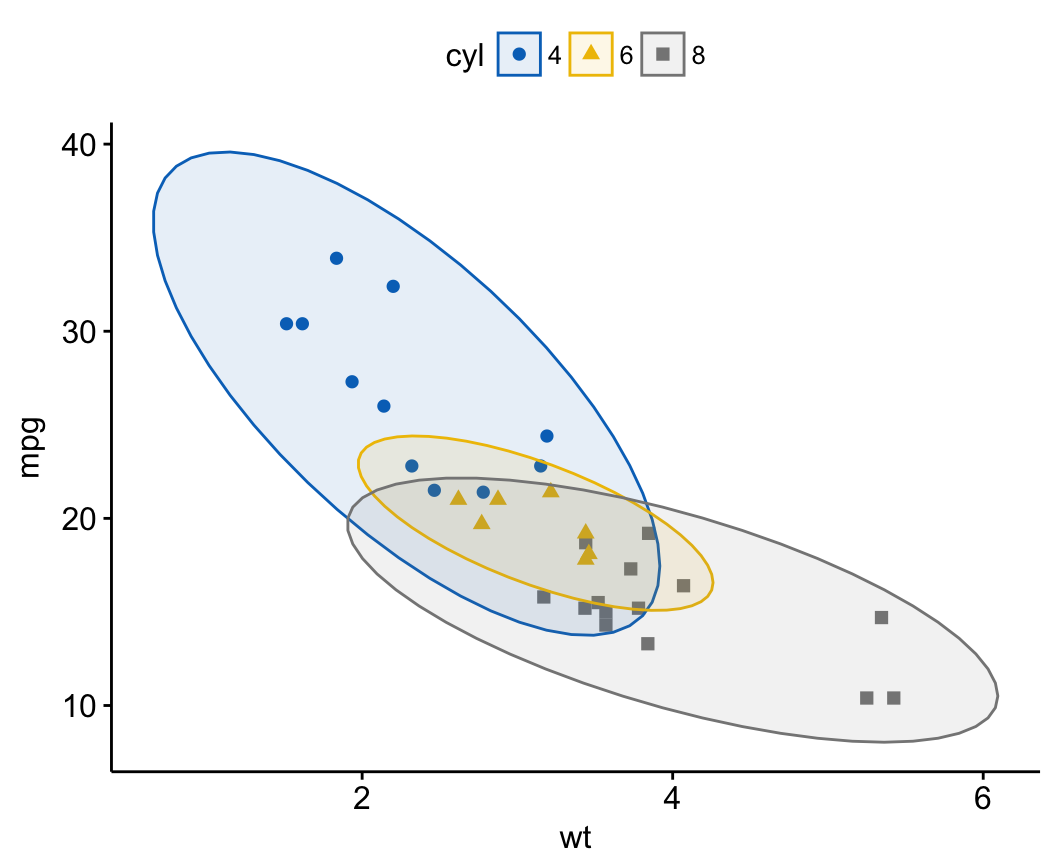
# Change the ellipse type to 'convex'
ggscatter(df, x = "wt", y = "mpg",
color = "cyl", palette = "jco",
shape = "cyl",
ellipse = TRUE, ellipse.type = "convex")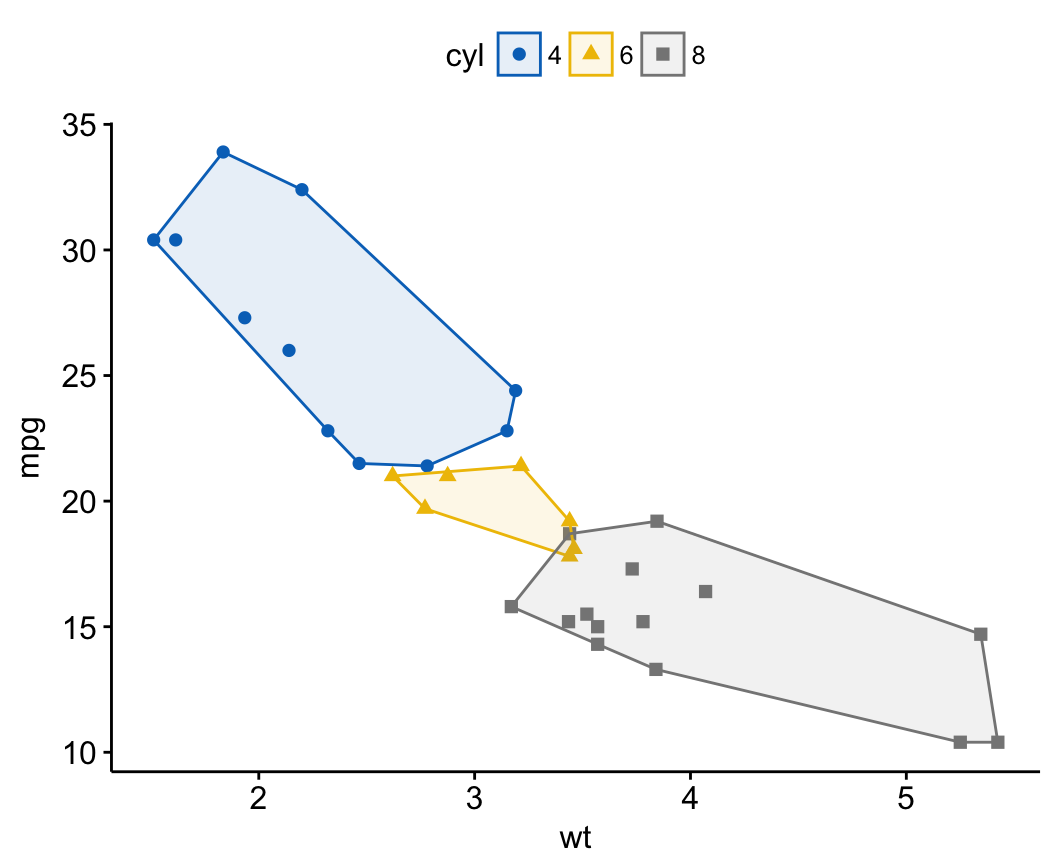
# Add group mean points and stars
ggscatter(df, x = "wt", y = "mpg",
color = "cyl", palette = "jco",
shape = "cyl",
ellipse = TRUE,
mean.point = TRUE,
star.plot = TRUE)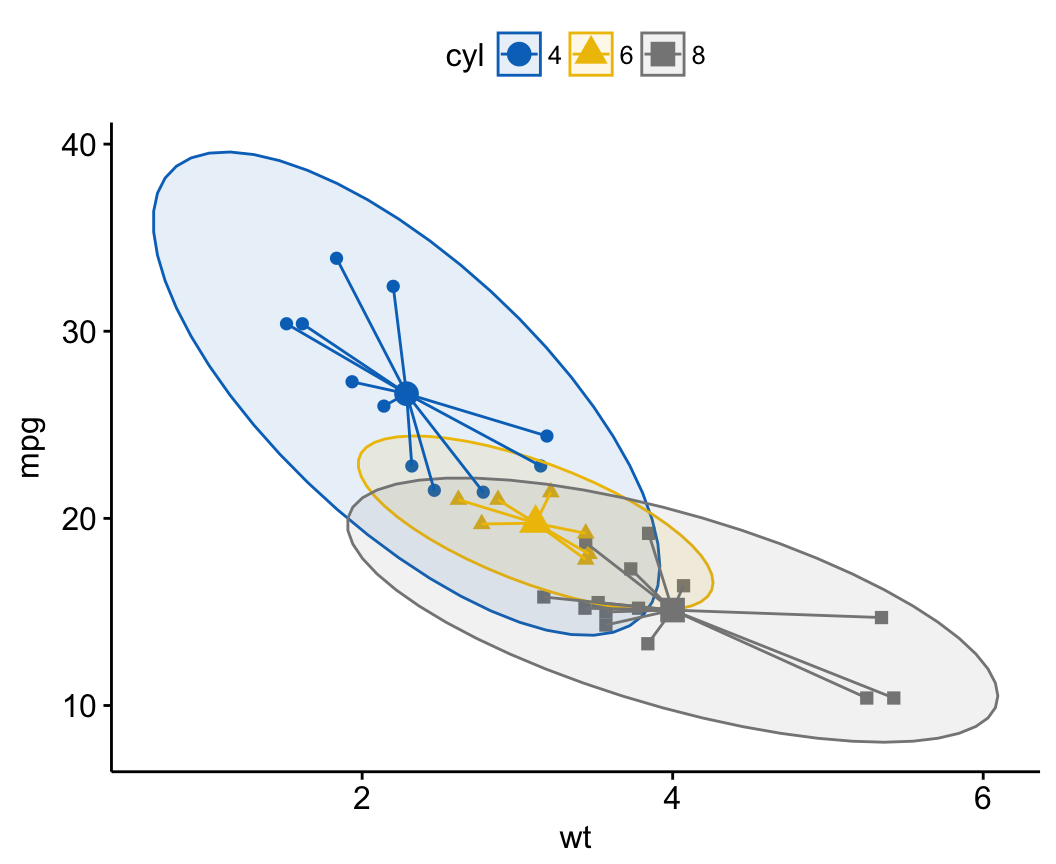
Add point labels
Main arguments:
- label: the name of the column containing point labels.
- font.label: a list which can contain the combination of the following elements: the size (e.g.: 14), the style (e.g.: “plain”, “bold”, “italic”, “bold.italic”) and the color (e.g.: “red”) of labels. For example font.label = list(size = 14, face = “bold”, color =“red”). To specify only the size and the style, use font.label = list(size = 14, face = “plain”).
- label.select: character vector specifying some labels to show.
- repel = TRUE: Avoid label overlapping.
# Use row names as point labels
df$name <- rownames(df)
ggscatter(df, x = "wt", y = "mpg",
color = "cyl", palette = "jco",
label = "name", repel = TRUE)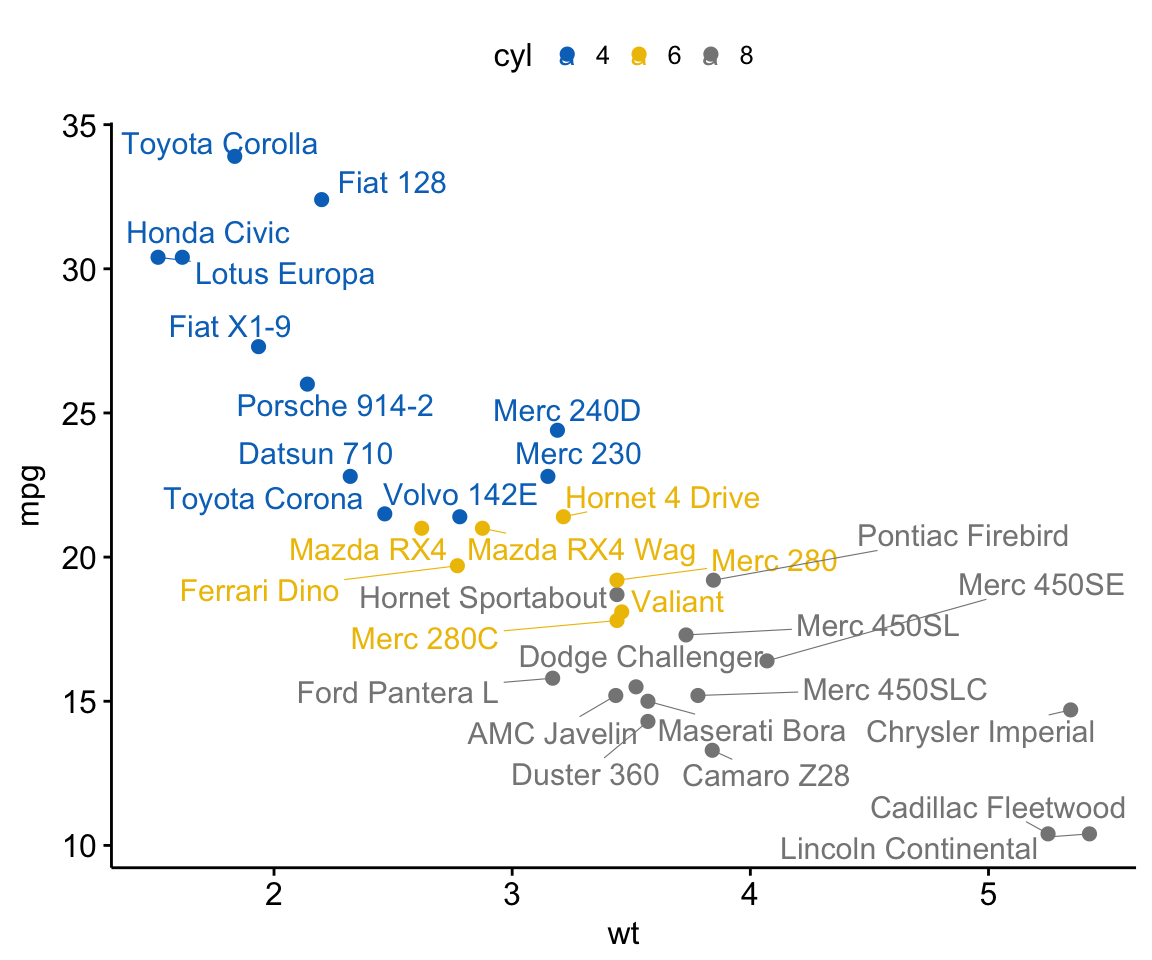
# Select some labels to show
ggscatter(df, x = "wt", y = "mpg",
color = "cyl", palette = "jco",
label = "name", repel = TRUE,
label.select = c("Toyota Corolla", "Merc 280", "Duster 360"))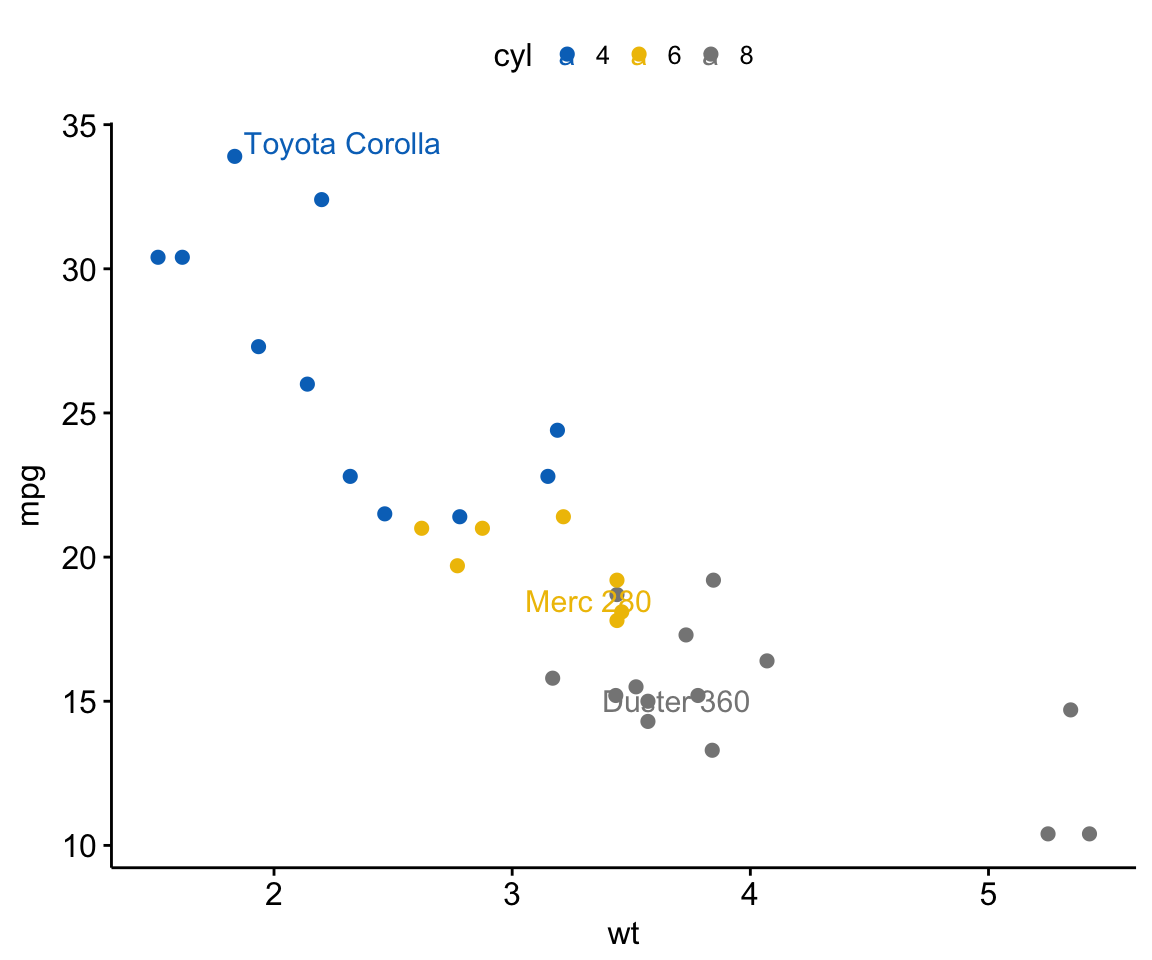
# Show labels according to some criteria: x and y values
ggscatter(df, x = "wt", y = "mpg",
color = "cyl", palette = "jco",
label = "name", repel = TRUE,
label.select = list(criteria = "`x` > 4 & `y` < 15"))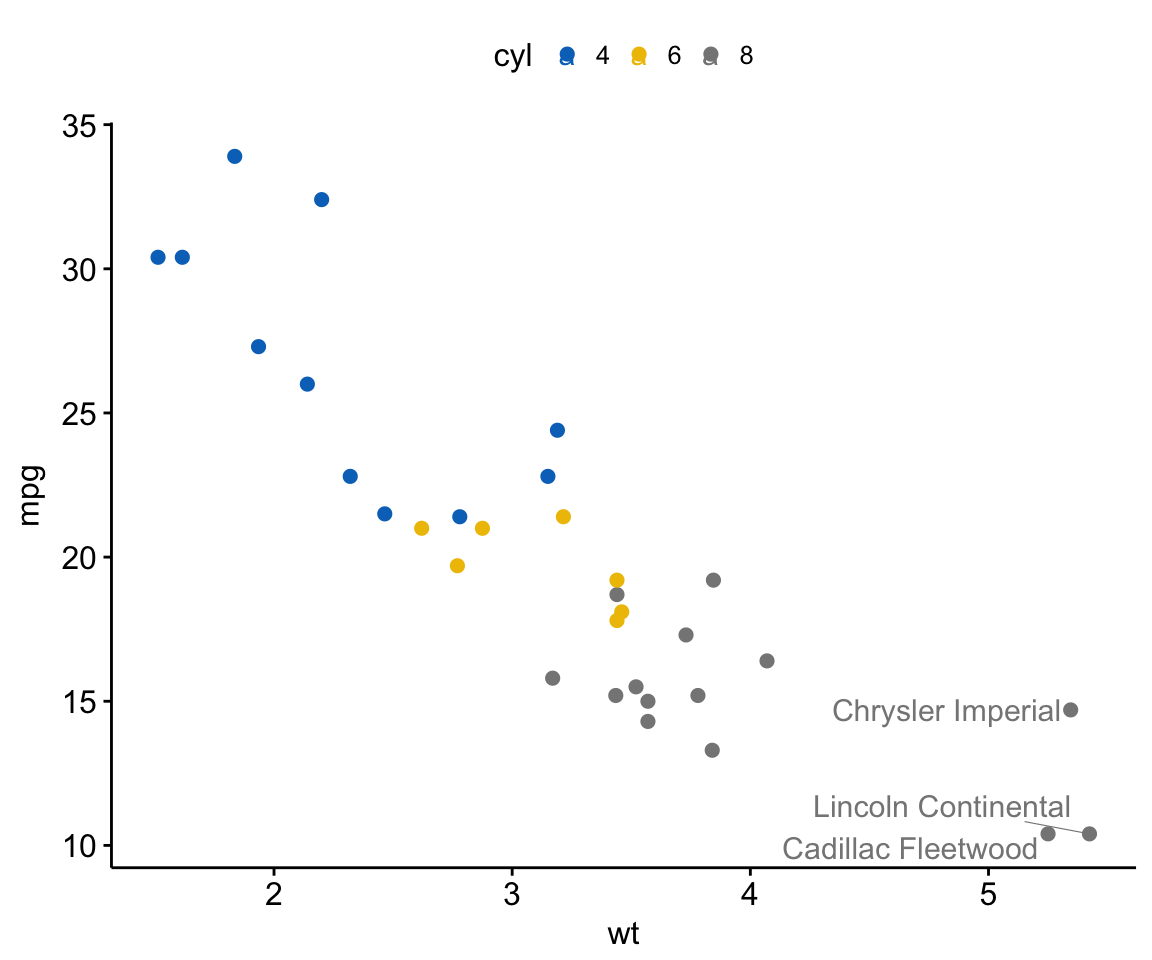
Bubble chart
In a bubble chart, points size is controlled by a continuous variable, here “qsec”. In the R code below, the argument alpha is used to control color transparency. alpha should be between 0 and 1.
ggscatter(df, x = "wt", y = "mpg",
color = "cyl", palette = "jco",
size = "qsec", alpha = 0.5)+
scale_size(range = c(0.5, 15)) # Adjust the range of points size
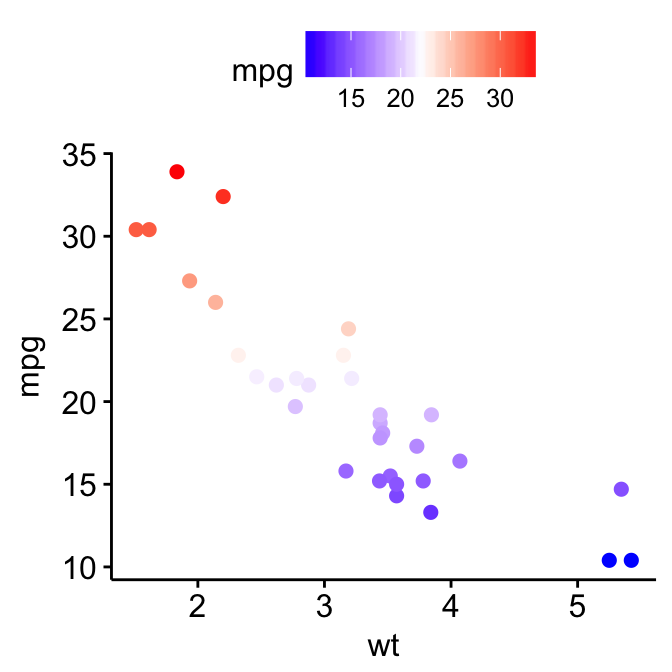
Color by a continuous variable
The R code below, will color points according to the values of a continuous variable, here “mpg”. By default, a blue gradient color is created. This can be changed using the helper function gradient_color() [in ggpubr].
# Color by continuous variable
p <- ggscatter(df, x = "wt", y = "mpg",
color = "mpg")
p
# Change gradient color
p + gradient_color(c("blue", "white", "red"))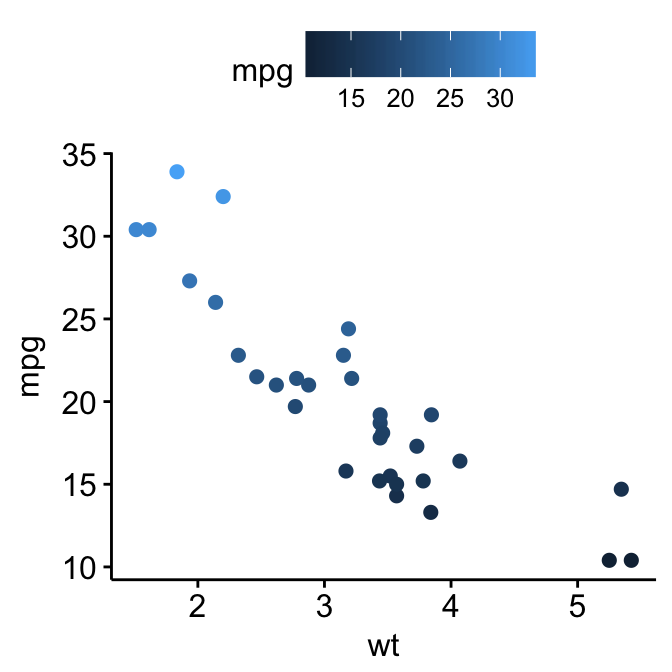
Add marginal plots
The function ggMarginal() [in ggExtra package], can be used to easily add a marginal histogram, density or boxplot to a scatter plot.
First, install the ggExtra package as follow: install.packages(“ggExtra”); then type the following R code:
# Add density distribution as marginal plot
library("ggExtra")
p <- ggscatter(iris, x = "Sepal.Length", y = "Sepal.Width",
color = "Species", palette = "jco",
size = 3, alpha = 0.6)
ggMarginal(p, type = "density")
# Change marginal plot type
ggMarginal(p, type = "boxplot")

One limitation of ggExtra is that it can’t cope with multiple groups in the scatter plot and the marginal plots. In the R code below, we provide a solution using the cowplot package.
# Scatter plot colored by groups ("Species")
sp <- ggscatter(iris, x = "Sepal.Length", y = "Sepal.Width",
color = "Species", palette = "jco",
size = 3, alpha = 0.6)+
border()
# Marginal density plot of x (top panel) and y (right panel)
xplot <- ggdensity(iris, "Sepal.Length", fill = "Species",
palette = "jco")
yplot <- ggdensity(iris, "Sepal.Width", fill = "Species",
palette = "jco")+
rotate()
# Cleaning the plots
sp <- sp + rremove("legend")
yplot <- yplot + clean_theme() + rremove("legend")
xplot <- xplot + clean_theme() + rremove("legend")
# Arranging the plot using cowplot
library(cowplot)
plot_grid(xplot, NULL, sp, yplot, ncol = 2, align = "hv",
rel_widths = c(2, 1), rel_heights = c(1, 2))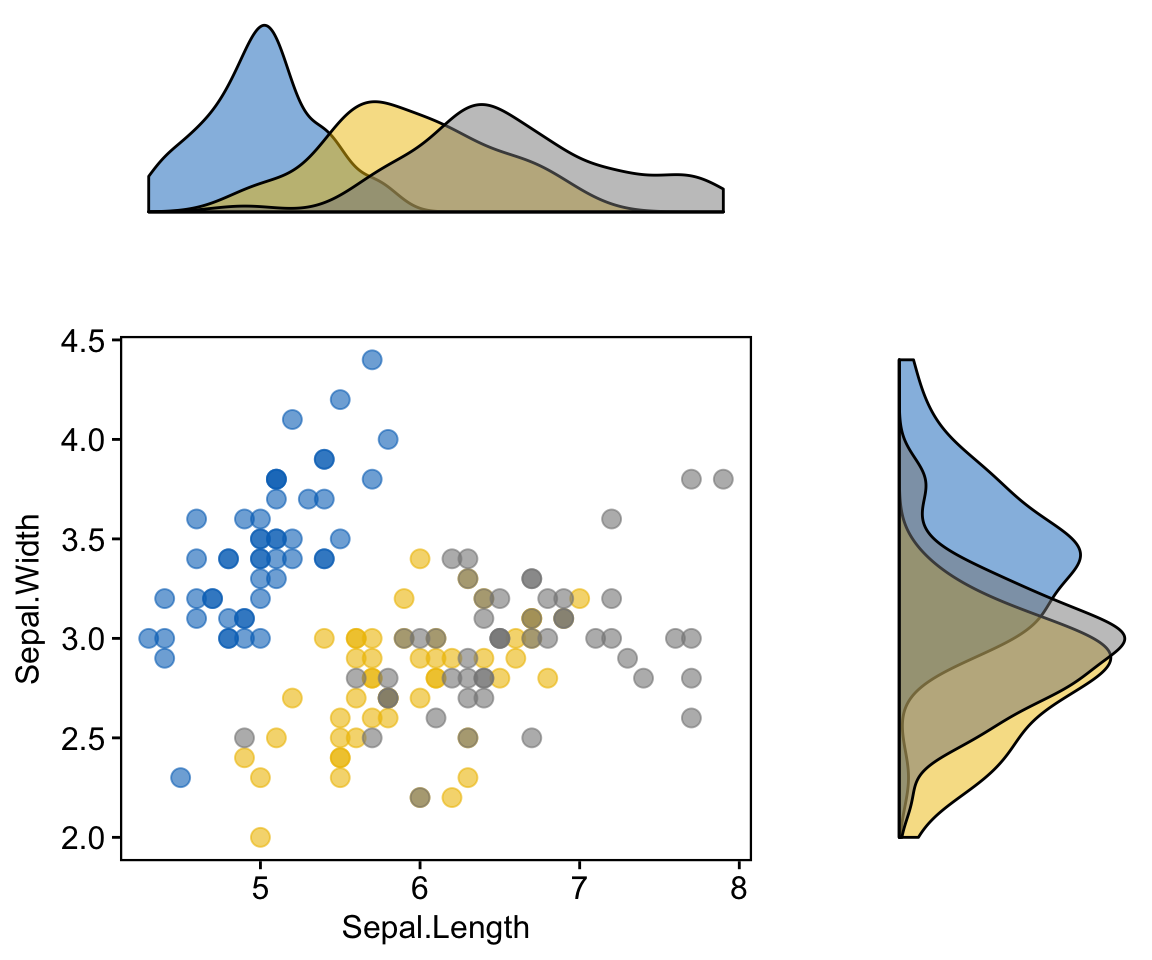
Add marginal boxplot:
# Scatter plot colored by groups ("Species")
sp <- ggscatter(iris, x = "Sepal.Length", y = "Sepal.Width",
color = "Species", palette = "jco",
size = 3, alpha = 0.6, ggtheme = theme_bw())
# Marginal boxplot of x (top panel) and y (right panel)
xplot <- ggboxplot(iris, x = "Species", y = "Sepal.Length",
color = "Species", fill = "Species", palette = "jco",
alpha = 0.5, ggtheme = theme_bw())+
rotate()
yplot <- ggboxplot(iris, x = "Species", y = "Sepal.Width",
color = "Species", fill = "Species", palette = "jco",
alpha = 0.5, ggtheme = theme_bw())
# Cleaning the plots
sp <- sp + rremove("legend")
yplot <- yplot + clean_theme() + rremove("legend")
xplot <- xplot + clean_theme() + rremove("legend")
# Arranging the plot using cowplot
library(cowplot)
plot_grid(xplot, NULL, sp, yplot, ncol = 2, align = "hv",
rel_widths = c(2, 1), rel_heights = c(1, 2))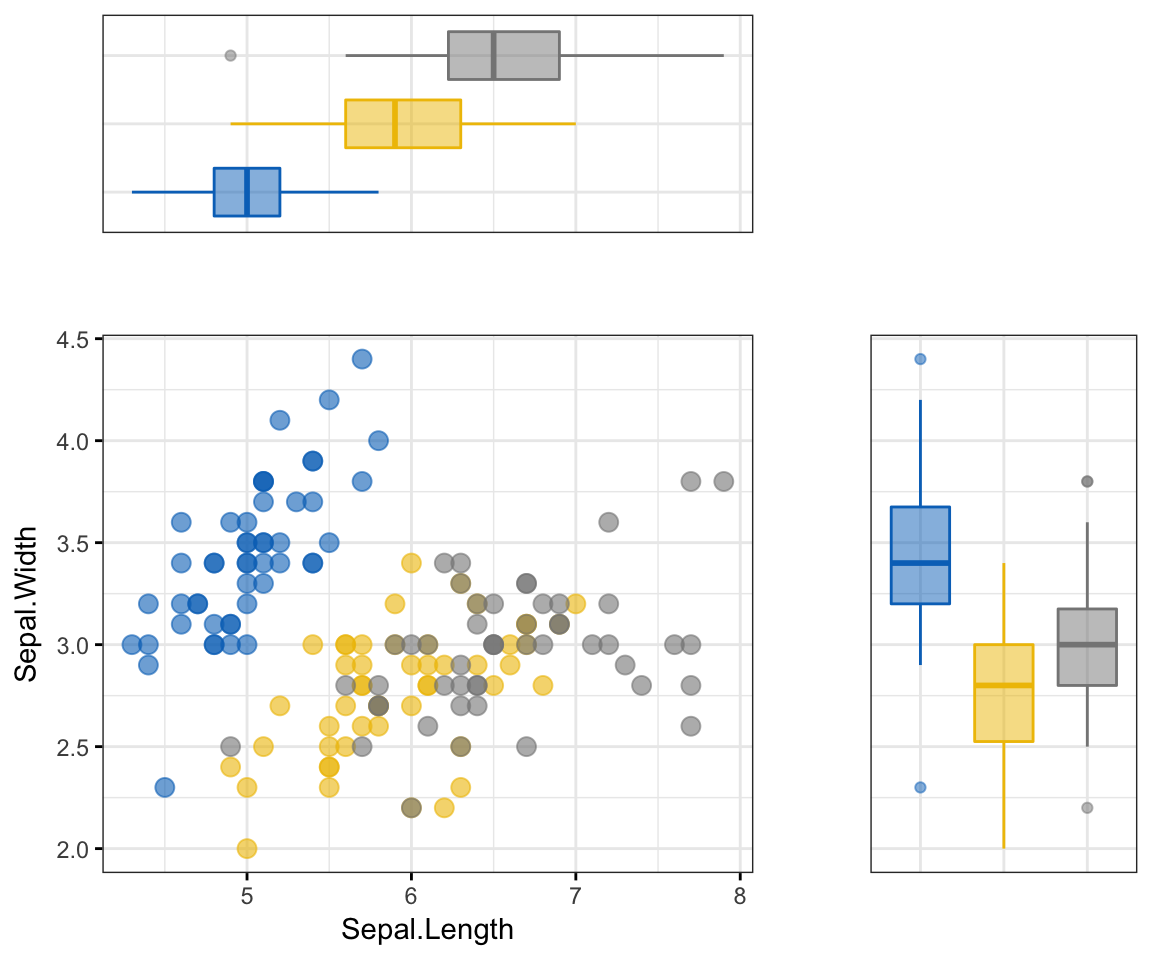
The problem with the above plots, is the presence of extra spaces between the main plot and the marginal density plots. Recently, in a tweet post, Claus Wilke provides the following solution for creating a perfect scatter plot with marginal density plots or histogram plots:
library(cowplot)
# Main plot
pmain <- ggplot(iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species))+
geom_point()+
ggpubr::color_palette("jco")
# Marginal densities along x axis
xdens <- axis_canvas(pmain, axis = "x")+
geom_density(data = iris, aes(x = Sepal.Length, fill = Species),
alpha = 0.7, size = 0.2)+
ggpubr::fill_palette("jco")
# Marginal densities along y axis
# Need to set coord_flip = TRUE, if you plan to use coord_flip()
ydens <- axis_canvas(pmain, axis = "y", coord_flip = TRUE)+
geom_density(data = iris, aes(x = Sepal.Width, fill = Species),
alpha = 0.7, size = 0.2)+
coord_flip()+
ggpubr::fill_palette("jco")
p1 <- insert_xaxis_grob(pmain, xdens, grid::unit(.2, "null"), position = "top")
p2<- insert_yaxis_grob(p1, ydens, grid::unit(.2, "null"), position = "right")
ggdraw(p2)
Add 2d density estimation
# Add 2d density estimation
sp <- ggscatter(iris, x = "Sepal.Length", y = "Sepal.Width",
color = "lightgray")
sp + geom_density_2d()
# Gradient color
sp + stat_density_2d(aes(fill = ..level..), geom = "polygon")
# Change gradient color: custom
sp + stat_density_2d(aes(fill = ..level..), geom = "polygon")+
gradient_fill(c("white", "steelblue"))
# Change the gradient color: RColorBrewer palette
sp + stat_density_2d(aes(fill = ..level..), geom = "polygon") +
gradient_fill("YlOrRd")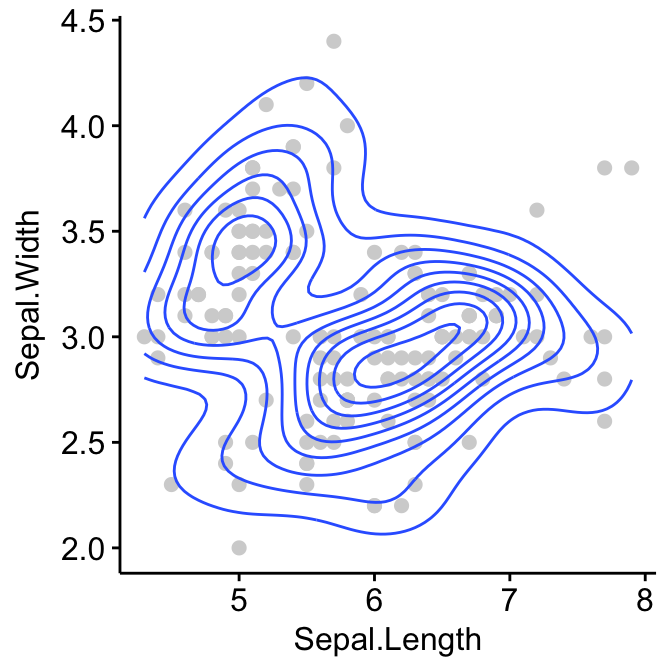
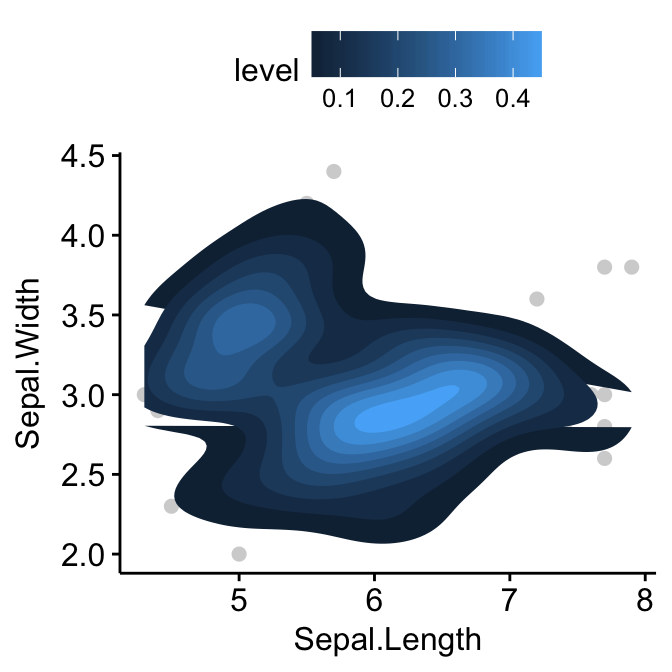
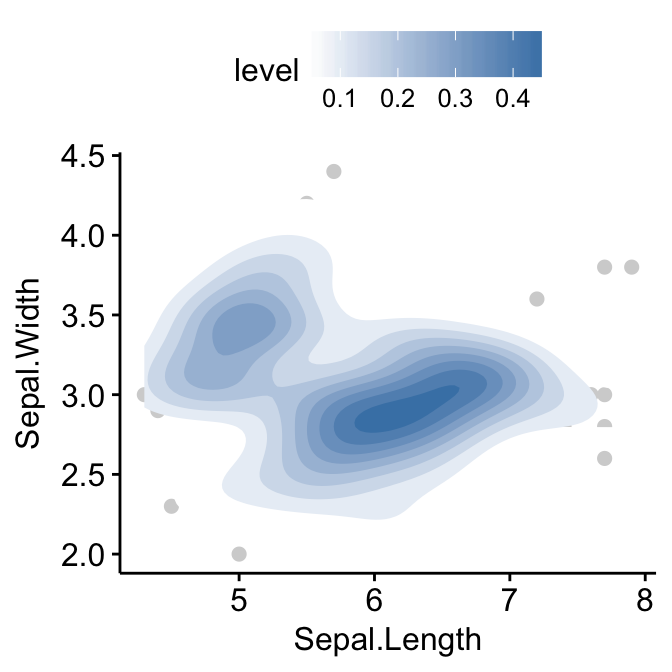
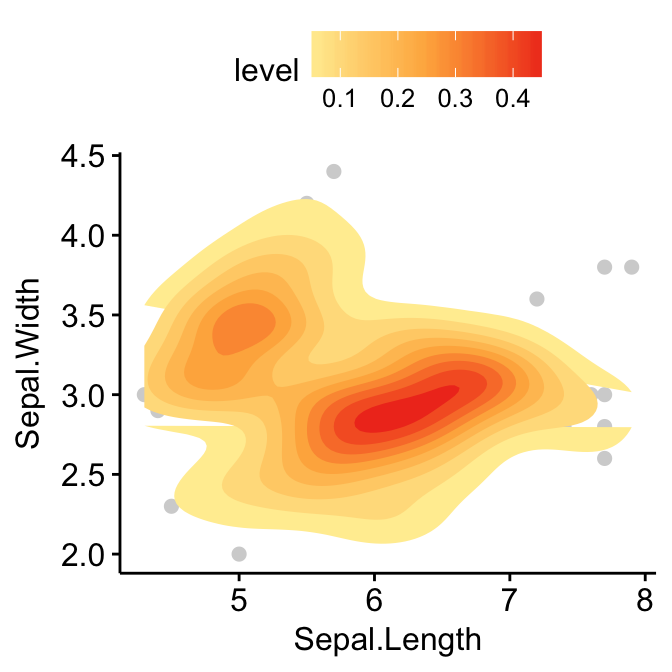
Application to gene expression data
We’ll use the gene expression data set described in our previous tutorial: Facilitating Exploratory Data Visualization: Application to TCGA Genomic Data.
expr <- read.delim("https://raw.githubusercontent.com/kassambara/data/master/expr_tcga.txt",
stringsAsFactors = FALSE)The data set contains the mRNA expression for five genes of interest - GATA3, PTEN, XBP1, ESR1 and MUC1 - from 3 different data sets:
- Breast invasive carcinoma (BRCA),
- Ovarian serous cystadenocarcinoma (OV) and
- Lung squamous cell carcinoma (LUSC)
The following plots show the association between GATA3 and ESR1 genes expression.
# Association between GATA3 and ESR1
# Color points by dataset
# Add correlation coefficient by dataset
ggscatter(expr, x = "GATA3", y = "ESR1", size = 0.3,
rug = TRUE, # Add marginal rug
color = "dataset", palette = "jco") +
stat_cor(aes(color = dataset), method = "spearman")
Facet/split by data set, add regression line and confidence interval:
ggscatter(expr, x = "GATA3", y = "ESR1", size = 0.3,
color = "dataset", palette = "jco",
facet.by = "dataset", #scales = "free_x",
add = "reg.line", conf.int = TRUE) +
stat_cor(aes(color = dataset), method = "spearman", label.y = 6)
Combining multiple plots. Visualize the correlation of GATA3 with two other genes (ESR1 and MUC1)
ggscatter(expr, x = "GATA3", y = c("ESR1", "MUC1"), size = 0.3,
combine = TRUE, ylab = "Expression",
color = "dataset", palette = "jco",
add = "reg.line", conf.int = TRUE) +
stat_cor(aes(color = dataset), method = "spearman")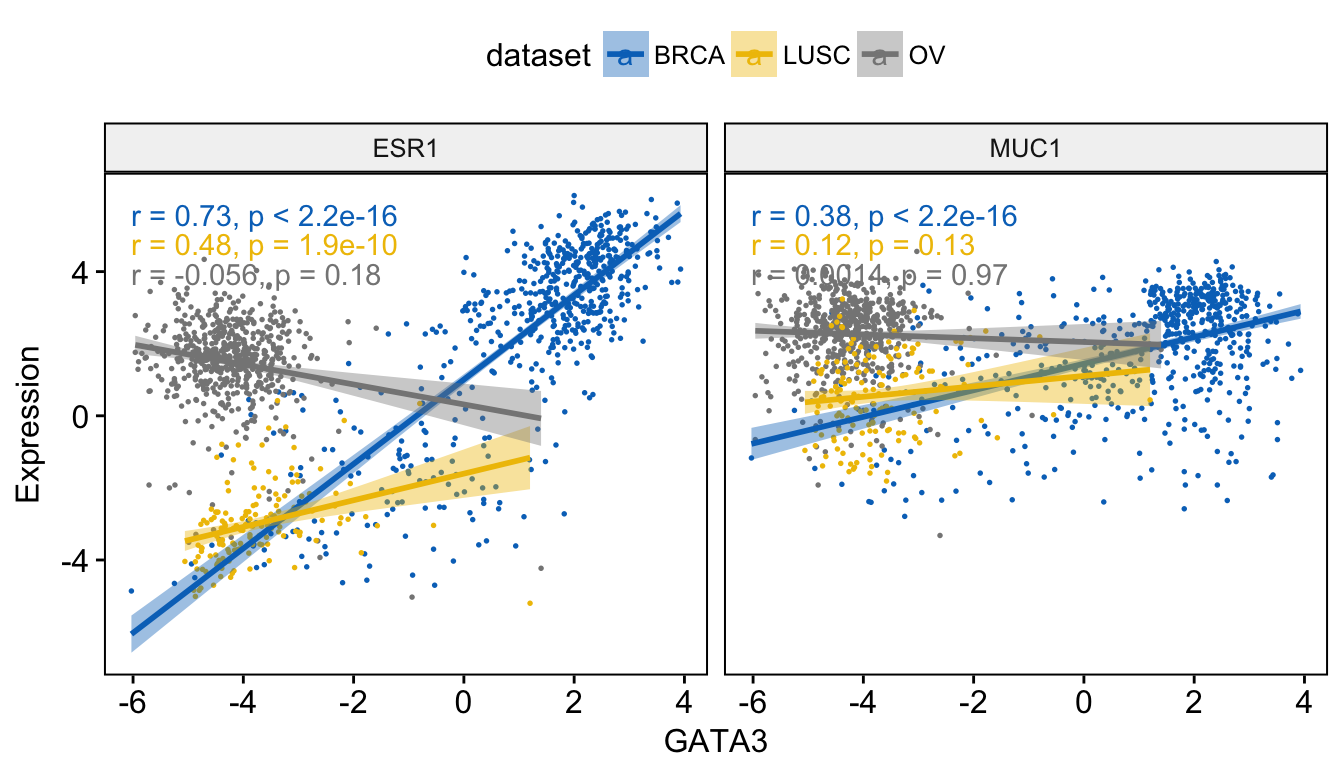
Further readings
See also the ggpmisc R package to add linear model equation to a scatter plot.